A Method for Emerging Empirical Age Structures in Agent-Based Models with Exogenous Survival Probabilities

and
The Alan Turing Institute, United Kingdom
Journal of Artificial
Societies and Social Simulation 27 (1) 8
<https://www.jasss.org/27/1/8.html>
DOI: 10.18564/jasss.5270
Received: 04-Apr-2023 Accepted: 01-Nov-2023 Published: 31-Jan-2024
Abstract
For many applications of agent-based models (ABMs), an agent's age influences important decisions (e.g. their contribution to/withdrawal from pension funds, their level of risk aversion in decision-making, etc.) and outcomes in their life cycle (e.g. their susceptibility to disease). These considerations make it crucial to accurately capture the age distribution of the population being considered. Often, empirical survival probabilities cannot be used in ABMs to generate the observed age structure. This may be due to discrepancies between samples (e.g. when empirical survival probabilities are calculated across the whole population, but only a sub-population is being modelled) or models (between the survival model underpinning the ABM and the statistical model used to produce empirical survival probabilities). In these cases, imputing empirical survival probabilities will not generate the observed age structure of the population, and assumptions such as exogenous agent inflows are required (but not necessarily empirically valid). In this paper, we propose a method that allows for the preservation of agent age-structure without the exogenous influx of agents, even when only a subset of the population is being modelled. We demonstrate the flexibility and accuracy of our methodology by performing simulations of several real-world age distributions. This method is a useful tool for those developing ABMs across a broad range of applications.Introduction
There exists a broad class of agent-based models (ABMs) in which (1) agents become older with time, (2) their survival probability is exogenous and dependent on age, (3) the population size is assumed constant, (4) the dynamics reach a steady state, and, sometimes, (5) their population does not cover the entire age spectrum. These ABMs are aimed at studying short-term problems such as unemployment and occupational transitions where steady-state dynamics and population conservation are desirable properties. Examples of such models can be found in labour studies (Axtell & Epstein 1999; Fair & Guerrero 2023; Goudet et al. 2017) (see Neugart & Richiardi (2018) for a comprehensive review), demography (Billari & Prskawetz 2003; Diaz et al. 2010), and microsimulation (Borella & Moscarola 2010; Cai et al. 2006; Leombruni & Richiardi 2006; Reznik et al. 2019). Frequently, these applications are not concerned with preserving the empirical age distribution of the (sub)population, but with accounting for empirical survival probabilities. In some cases, preserving the real age distribution is a priority, for example, when focusing on the adult labour force with the aim of studying retirement- and life-cycle-related problems. Often, and especially when working with sub-populations, ABMs fail at preserving the empirical age distributions if supplied with official survival probabilities. This problem arises from a mismatch between the assumed statistical model used in survival analysis and the one underlying the ABM, as well as in the populations covered.
A naive approach to preserve the age structure of a sub-population is to re-sample the empirical age distribution whenever an agent dies. While this indeed solves the preservation problem, it is not ideal in applications that study the life cycle of the agent, for example, when considering career progression. Two other popular remedies are imposing coarse age bins and exogenous migration inflows. The former destroys information on age structure that could be useful to address problems related to highly stratified populations. The latter (migration flows) may not be empirically valid (or observed), but rather an artefact to generate the empirical age distributions. An alternative framework aiming at preserving the first two moments of the age distribution has been proposed by Schindler (2012). This approach also has limits as nuanced structures in the shape of the distribution may be key for applications related to the life cycle of the agent.
In this paper, we develop a method to estimate age-specific survival probabilities that generate arbitrary age structure in an ABM that meets the first four conditions mentioned above.1 Our method consists of a stochastic process of an ageing population and a solution for arbitrary steady-state age distributions (i.e. age distributions that remain constant in time, in both size, and in the proportion/number of individuals within each age class). The solution yields a vector with age-specific survival probabilities that guarantees the emergence of the desired age structure (but that may differ from official survival probabilities). These survival probabilities can then be imputed in an ABM that considers an ageing process with exogenous survival probabilities. We emphasise that these probabilities should not be interpreted as those that come from survival functions estimates, instead they embed assumptions that are relevant to the types of ABMs we focus on here.
Method
We begin by describing the stochastic process that generates the desired steady-state age distribution. Then, we outline an extended version of this model that provides more flexibility in terms of the age distribution shapes, and the method used to parameterise it.
Model 1: Simple stochastic process
Let us explain the method through the example of a labour market model focusing on adult age groups, from 18 years old to 90 or more years old. Consider the distribution of the agents across these age groups as \(N_{18}, N_{19}, \dots, N_{90+}\). For each of these groups, their survival probabilities are \(p_{18}, p_{19}, \dots, p_{90+}\). The stochastic process consists of a population with \(N\) agents, each one ageing by one year each period and surviving with the probability of their age group. Every time an agent dies, it is replaced by a new agent that is 18 years old. Thus, the model assumes a constant population, and ensures that all agents have gone through the same life cycle process.
We can describe the dynamics of this system through the changes of the age groups. Because of the specifics of the agent-replacement rules, we need to write three different evolution equations: one for the 18-years old group, another for the 90+ group, and another for all those groups in between these two. Let us begin with the 18-years old one, which is given by:
| \[N_{18,t+1} = N_{18,t} - p_{18}N_{18,t} + (1-p_{19})N_{19,t} + (1-p_{20})N_{20,t} + \dots + (1-p_{90+})N_{90+,t}\] | \[(1)\] |
The dynamics of the second type can be described as:
| \[N_{90+,t+1} = N_{90+,t} - (1-p_{90+})N_{90+,t} + p_{89}N_{89+,t}\] | \[(2)\] |
Finally, the third type consists of any age group \(18 < i < 90\), and can be described by:
| \[N_{i,t+1} = N_{i,t} - (1-p_i)N_{i,t} - p_iN_{i,t} + p_{i-1}N_{i-1,t}\] | \[(3)\] |
This stochastic process leads to a steady state. In such state, it is safe to assume \(N_{i,t+1} = N_{i,t}\) for any age group. Therefore, by simplifying the three equations and re-arranging them, we can write down the linear system
| \[\begin{split} -p_{18}N_{18,t} + (1-p_{19})N_{19,t} + \dots + (1-p_{90+})N_{90+,t} = 0\\ \vdots\\ 0 + \dots + p_{i-1}N_{i-1,t} - N_{i,t} + \dots + 0 = 0\\ \vdots\\ 0 + \dots + p_{89}N_{89+,t} - (1-p_{90+})N_{90+,t} = 0 \end{split},\] | \[(4)\] |
| \[\begin{bmatrix} -p_1 & (1-p_2) & (1-p_3) & (1-p_4) & (1-p_5) & \dots & (1-p_n) \\ p_1 & -1 & 0 & 0 & 0 & \dots & 0 \\ 0 & p_2 & -1 & 0 & 0 & \dots & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & \dots & p_{i-1} & -1 & 0 & \dots & 0 \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \dots & p_{n-1} & -(1-p_n) \\ \end{bmatrix} \begin{bmatrix} N_1 \\ N_2 \\ N_3 \\ \vdots \\ N_i \\ \vdots\\ N_n \\ \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ \vdots \\ 0 \\ \vdots\\ 0 \\ \end{bmatrix}\] | \[(5)\] |
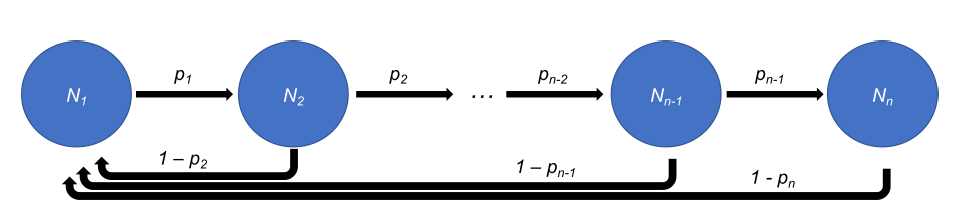
Thus, in general, for some system with \(n\) age groups, we obtain:
| \[\begin{split} p_{i-1}= N_{i,t}/N_{i-1,t} \ \forall \ i \in \{2, \dots, n-1\}\\ p_{n-1}= (1-p_{n})N_{n,t}/N_{n-1,t} \\ \end{split}\] | \[(6)\] |
| \[-p_{1}N_{1,t} + (1-p_{2})N_{2,t} + \dots + (1-p_{n})N_{n,t} = 0\] | \[(7)\] |
If we add the constraint that \(p_{i} \in [0,1] \ \forall \ i \in \{1, \dots, n-2\}\) then, assuming \(N_{i,t} > 0\), we obtain:
| \[\begin{split} % 0 \leq N_{i+1,t}/N_{i,t} \leq 1 \ \forall \ i \in \{1, \dots, n-2\} \\ 0 \leq N_{i+1,t} \leq N_{i,t} \ \forall \ i \in \{1, \dots, n-2\} \end{split}\] | \[(8)\] |
| \[\begin{split} % 0 \leq (1-p_{n}) N_{n,t}/N_{n-1,t} \leq 1 \\ % \Rightarrow 0 \leq (1-p_{n}) \leq N_{n-1,t}/N_{n,t} \\ 1 - N_{n-1,t}/N_{n,t} \leq p_{n} \leq 1 \end{split}\] | \[(9)\] |
This condition means that, for this model specification, the types of age distributions that will emerge have a structure where the number of individuals in a group decreases monotonically with age; something common in many countries, at least approximately. Next, let us generalise the stochastic process to allow for the emergence of age distributions (which can also be empirically observed) where this monotonic pattern does not hold.
Model 2: Process with activation rates
Assume that, in addition to the previous model, there is an activation process (see Axtell (2000) for a review of different activation regimes). In Axtell (2000), the author describes activation functions as the probability functions with which an agent in an ABM ‘wakes up’ and performs an action. Thus, in the context of our model, agents are subjected to the ageing process only if they are active. Conceptually, this assumption may come across as a strange one. However, as we show ahead, it allows more flexibility in the types of age distributions that can emerge from the stochastic process.
If introducing this assumption does not affect the model’s interpretation and results in a substantial way, it could be useful to capture other observed age structures in an ABM.2 As demonstrated in Huberman & Glance (1993) using a spatial Prisoner’s Dilemma model introduced by Nowak & May (1992), and in Axtell (2000) using a model of firm formation (Axtell, 1999) and previous results from a model of cultural transmission (Axtell et al. 1996), the way activation rates are incorporated into model structure does in some cases alter model outputs. Thus, we echo Axtell (2000) in emphasising that the impact of introducing activation rates should be investigated, and this investigation should factor into the decision whether or not to include activation rates in a model.
The activation process in model 2 is governed by a vector of activation rates \(\alpha_i, \dots, \alpha_n\). Parameter \(\alpha_i\) determines the activation rate when the agent belongs to age group \(i\). This model is described in Figure 2.
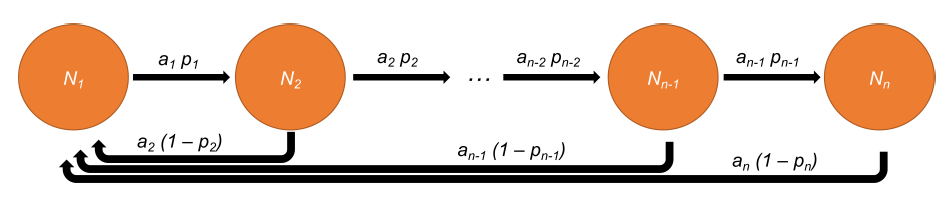
Let us focus on the equation describing the intermediate groups, which was given by:
| \[N_{i,t+1} = N_{i,t} - (1-p_i)N_{i,t} - p_iN_{i,t} + p_{i-1}N_{i-1,t}\] | \[(10)\] |
| \[p_{i-1} = N_{i,t}/N_{i-1,t} \ \forall \ i \in \{2, \dots, n-1\}\] | \[(11)\] |
With the addition of an activation regime, the evolution of intermediate groups is:
| \[N_{i,t+1} = N_{i,t} - \alpha_{i}(1-p_i)N_{i,t} - \alpha_{i}p_iN_{i,t} + \alpha_{i-1}p_{i-1}N_{i-1,t}\] | \[(12)\] |
| \[p_{i-1} = \frac{\alpha_{i}N_{i,t}}{\alpha_{i-1}N_{i-1,t}} \ \forall \ i \in \{2, \dots, n-1\}\] | \[(13)\] |
| \[p_{n-1} = \frac{\alpha_n (1-p_n)}{\alpha_{n-1}} \frac{N_{n,t}}{N_{n-1,t}}\] | \[(14)\] |
Similarly to the model without activation rates, \(p_n\) is left as a free parameter, and we require that \(p_i, \alpha_ i \in [0,1] \ \forall \ i \in \{ 1, \dots, n\}\).
Parameterisation
The parameterisation method depends on which of the two models is being used to generate the age distribution. For the model without activation rates (model 1), the user simply chooses a value for the free parameter (\(p_n\)) and uses this to calculate the value of \(p_{n-1}\), with all \(p_i\) for \(\ i \in \{1, \dots, n-2\}\) determined wholly by the observed age distribution. When using model 2 – the model with activation rates (\(\alpha_i\) for \(i \in \{1, \dots, n \}\)) – the process of determining suitable parameter values becomes more complicated as there is no general solution for \(\alpha_i\). Here, we use the heuristic optimisation method of differential evolution to determine suitable parameter values. In many cases, the optimisation algorithm is able to quickly (both in terms of number of iterations, and in terms of total computational time) determine parameter values that allow the model to replicate the desired age distribution with a high degree of accuracy. However, for some age distributions, even the addition of activation rates will not provide sufficient flexibility to admit parameter values allowing the model to produce a reasonably accurate age distribution. In these cases, we suggest the curve-fitting procedure explained below.
Fitting distributions
There exist cases in which the structure of an observed age distribution cannot be generated by either of the two stochastic processes. In these cases, we suggest modifying the empirical distribution by changing it into a distribution that fulfils the conditions established by the first stochastic process (the one without activation rates). We can determine the modified distribution by fitting a condition-compliant function to the empirical data to create a modified age distribution. Determining whether this is a reasonable course of action depends on how different the fitted distribution looks with respect to the original one. This can be determined by calculating the Wasserstein metric, indicating the minimum amount of “work” required to convert the original distribution to the fitted one (Kantorovich 1960; Vaserstein 1969). Section 3.5 shows that, in many real-world cases, adopting this procedure is a sensible choice.
First, let us define the condition-compliant function given by:
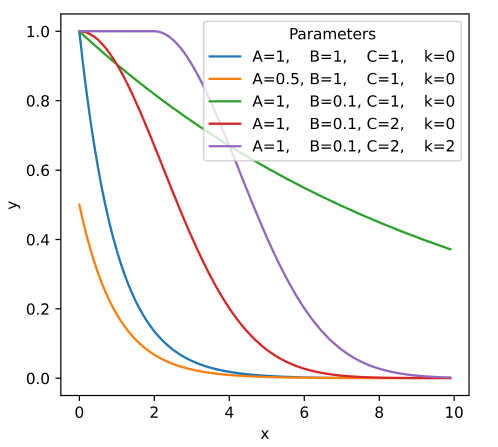
| \[y(x) = \begin{cases} A \ \text{for} \ x < k, \\ A e^{-B(x-k)^C} \ \text{for} \ x \geq k \end{cases} \] | \[(15)\] |
Consider only the points \(x \in \{1, \dots, n \}\) such that the values obtained correspond to the proportion of individuals within each age group in the distribution. The value \(k\) is some integer that demarcates between the younger age groups assumed to contain equal proportions of individuals, and the older age groups where the proportion of individuals within a group decreases with the age of that group. For example, \(k=5\) would indicate that the age group will be where we shift between the cases in Equation 15.
Values for \(A, B, C\) are determined by fitting Equation 15 to the observed age distribution using a non-linear least squares method for each possible \(k\)-value, where \(k \in \{1, \dots, n\}\). The best set of fitted parameters is determined based on which \(k\)-value (and associated values for \(A, B, C\)) minimises the value of the Wasserstein metric. Selecting the parameter set which leads to the lowest value of the Wasserstein metric ensures that our fitted age distribution departs from the original distribution as little as possible.
Applications
We demonstrate the features of our modelling framework by using age distributions with 5-year age groups (0-4, 5-9, …, 95-99, 100+) at the “Country/Area" (hereafter referred to as country) level for the year 2019 (United Nations 2019). It is important to note that these broad age groups are chosen based on the granularity of the data, and do not reflect a requirement of the model, which admits age groups of any”width". We show different cases using several countries. First, we begin with the stochastic process without activation rates (model 1). Then we demonstrate use of the model with activation rates (model 2). Finally, we use the curve-fitting approach combined with model 1. In all cases, we run simulations for 350 timesteps (such that they reach the steady state) with a population of 10,000 agents.
Using model 1
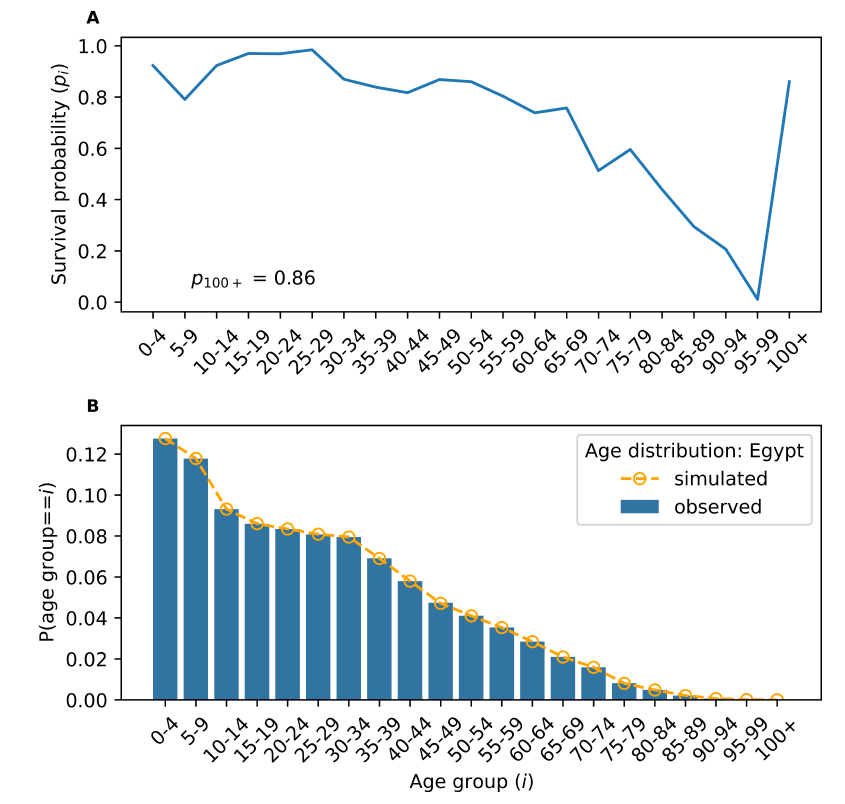
Egypt is an example of a population with monotonically decreasing age group sizes. In other words, it exhibits the stylised fact of a population pyramid with its base found in the youngest cohort. Of the 201 countries included within our dataset, 57 (roughly 28%) exhibit age distributions of this type. These age distributions fulfil the parameter conditions set by model 1, so we can use this stochastic process. This also means that, by solving the implied system of this stochastic process, we can directly obtain the survival probabilities needed to generate such age structures. Figure 4 demonstrates this by showing the age group survival probabilities and a perfect match between Egypt’s empirical distribution and the steady-state age distribution produced by the model.
Using model 2
In Equatorial Guinea the population’s age structure does not exhibit the pyramid stylised fact, so group size does not decrease monotonically with age. This means that we cannot use model 1, as its parameter conditions are not met. Instead, we use the model with activation rates (Figure 5) as it allows more degrees of freedom.3 Figure 5 shows, in the top panel, the age group survival probabilities and activation rates needed to generate Equatorial Guinea’s age distribution. The bottom panel demonstrates that, by using model 2, we get a highly accurate match between the steady-state age distribution and the empirical one with its characteristic hump in the 20-to-30 age groups.
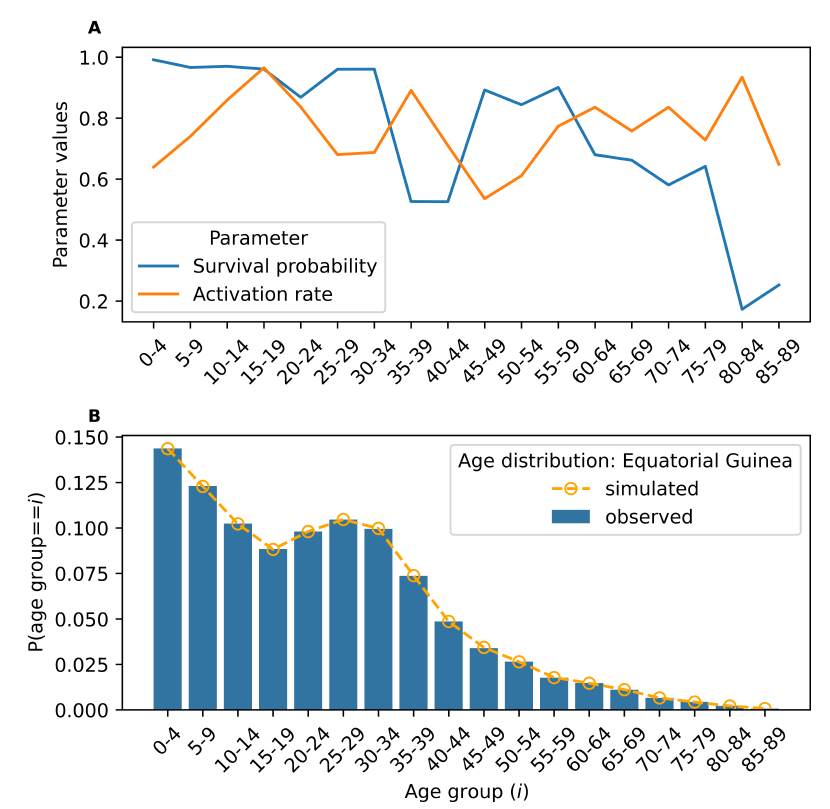
Of the 144 countries that do not exhibit monotonically decreasing age distributions (where model 1 is ideal), we find that 45 can be successfully simulated using model 2. If the mean absolute error between the simulated distribution and the observed age distribution is below a threshold of \(1 \times 10^{-4}\), we assume this model is successful. If we cannot arrive at a combination of survival probabilities and activation rates that achieve this level of accuracy for a given country within 250 iterations of the optimisation method, we assume that model 2 is unsuitable for simulating that country’s age distribution. For countries falling into this group, we use the curve-fitting procedure.
Curve-fitting procedure
The United Kingdom (UK) is representative of the age structure of several European nations with a large ageing population. Here, we observe that the largest groups are in their 30s and 50s. The youngest groups are smaller, but not in a drastic way, giving the distribution a flat structure across the ages 0 to 59 years. By looking at this stylised shape, it is clear that fitting Equation 15 to the data is a sensible choice.
The UK is one of 99 countries for which neither model 1 nor model 2 prove suitable, and for which we apply the curve fitting procedure. The distribution of the Wasserstein metric values for these 99 countries is shown in Figure 6, with 56 countries having below-average metric values. The UK is one of these 56 countries, with a Wasserstein metric value of approximately \(0.0027\). This indicates that the fitted UK age distribution is quite similar to the observed distribution (in the context of the group of age distributions we consider). This further affirms our intuition that it would be sensible to apply the fitting method to the UK’s age distribution. Thus, we fit and use model 1 to obtain the survival probabilities that allow the stochastic process to generate the fitted distribution. Panel A in Figure 7 shows the estimated survival probabilities. Panel B shows the empirical UK age distribution, the fitted one, and the steady-state one generated by model 1.
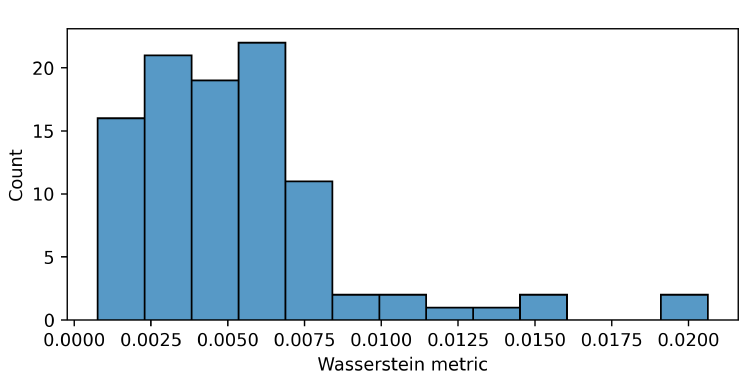
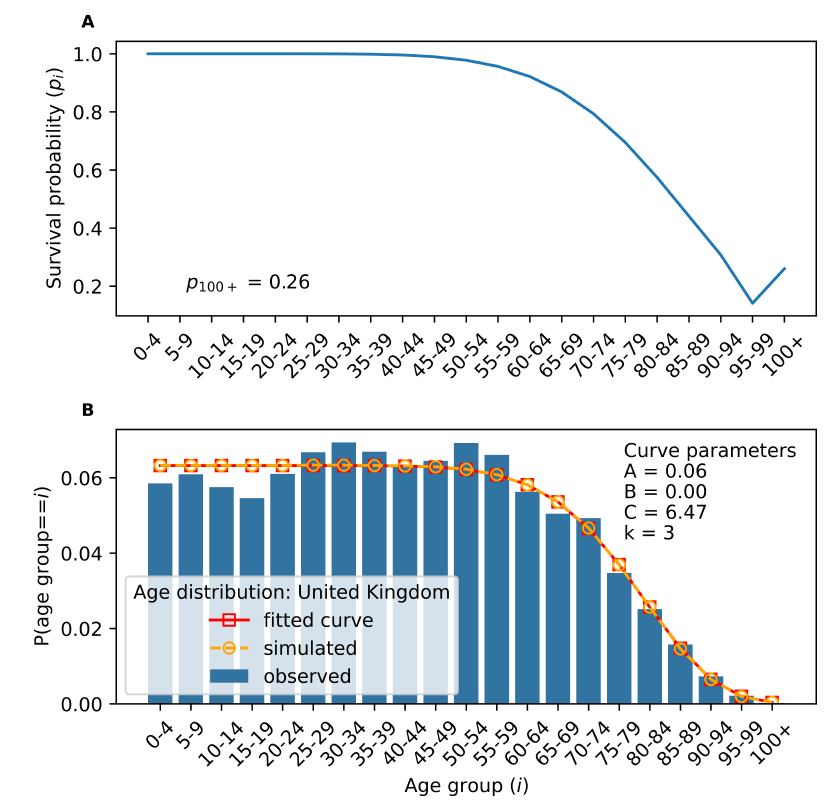
In summary, the proposed method is able to provide the parameters needed to generate a large number of empirical age distributions for agent-based models fulfilling the characteristics enlisted in the introduction of this paper. Our examples show its versatility using country-level real-world data. Next, we close the paper with a summary and discussion on our findings and the contribution of the method.
Discussion and Conclusions
Limitations
The main limitation of the proposed method is that it only applies to ABMs with steady-state population dynamics with exogenous survival probabilities. This means that, in systems where the probability of surviving is affected by an endogenous variable–such as an infectious disease–it would not be possible to calculate the survival probabilities needed to generate a target age distribution. Potential future extensions could consider more elaborate stochastic processes that incorporate such variables.
Another limitation is that we assume a constant population size in the ABM that needs to be calibrated. Extending the model to a growing population introduces some complications such as the loss of conservation restrictions in the system of equations that needs to be solved. Non-conservative models are common in population ecology, where researchers tends to focus on using observed rates (of survival and of fecundity) to make predictions about the steady-state distribution of ages/life stages. In many social systems, we have the opposite problem: given a known steady-state age/life distribution, we need to determine survival probabilities and activation rates that will lead to the desired steady-state distribution. In fact, models 1 and 2 are the social analogues to the popular Leslie (Leslie 1945, 1948) and Lefkovitch (Lefkovitch 1965) matrices found in population ecology. Another potential direction of future research is to extend our models to consider non-conservative populations and to uncover a more direct connection with the population ecology literature.
On the evolution of the age distribution
A potential concern with our method is that the dynamics of age distributions are not considered. We believe that this is not a fundamental problem, as there are ways in which steady-state transitions could be induced through a careful specification of the survival probabilities across time. In fact, a common practice in the ABM and micro-simulation communities is to initialise a model with the empirical age structure and survival probabilities, let it run, and interpret the final age distribution demographic forecast. We advise against this practice as, often, initialising an ABM with empirical data does not guarantee that the system has stabilised in a state that would be representative of the real world. Quite the opposite, a data-induced initialisation may generate transient dynamics that do not reflect the natural evolution of the system; i.e. it would only yield a calibration artefact. Instead, we recommend to first obtain stable dynamics such as those of a steady state. In the context of demographic change, calibrating for steady-state dynamics is a reasonable approach. For instance, consider conducting a census to construct the age distribution of a population. If one would repeat this exercise a year later, it would be unlikely to observe a radical shift in the age structure. Such shifts tend to be generational, and are usually considered to be of a long-term nature. Thus, by initialising an ABM in a steady state, one is simply assuming we are capturing some of the short-term dynamics taking place in the real world. Then, we can proceed to perturb the system to analyse long-term changes.
One particular type of perturbation is precisely the inter-temporal change of survival probabilities. For example, suppose that one is interested in studying the labour-market impacts of an age structure transition from a pyramid-shape distribution to an inverted-pyramid one (the latter perhaps predicted by a demographic model). If one would know the initial and final shapes (or even the intermediate), then our method can be applied to obtain the survival probabilities that yield such distributions in the steady state. These parameters can be progressively imputed in the model as it moves from one steady state to another, just as demographics change marginally in short periods. This strategy would reduce potential biases from the transient dynamics introduced by a purely empirical initialisation, and provide a more reliable way to study the nuanced impacts of a changing age distribution.
Conclusions
This paper introduces a method for generating steady-state age distributions in agent-based models developed to study short-term problems (e.g. unemployment). We highlight the flexibility of this method by illustrating its use on several country-level age distributions differing in shape. These results demonstrate the ease with which our method can be implemented across a broad range of scenarios.
Users should consider the type of age distribution they are interested in when deciding which of the three approaches to employ, as their efficacy depends on the relative sizes of the age groups within the population. As a rule of thumb for determining which model to try first, we suggest the following. The model without activation rates (model 1) is suitable for modelling populations with expansive population pyramids. The model with activation rates (model 2) may be useful for modelling populations with stationary or constrictive population pyramids (with a hump). Finally, using a combination of curve-fitting and model 1 may be successful for some populations with stationary population pyramids.
Acknowledgements
We are thankful to Robert Axtell for his insightful comments on the links between this work and population ecology. We are also grateful to Mark Birkin for his micro-simulation insights. Finally, we thank the anonymous referees for their useful comments on this manuscript.
This work was supported by Wave 1 of The UKRI Strategic Priorities Fund under the EPSRC Grant EP/W006022/1, particularly the “Shocks and Resilience” theme within that grant & The Alan Turing Institute.
Code availability
Code used for data analysis, parameter fitting, and simulation is available in a GitHub repository: https://github.com/k3fair/agedist-gen.
Notes
- A large part of the ABM demographic literature is concerned about population growth and changes in the age distribution. This method does not address those problems, but only the subset of models that meet the aforementioned characteristics. Likewise, public health scholars may be interested in endogenous survival probabilities (e.g., as a result of transmissible diseases). Our approach is not designed to be used with such models as the survival probabilities need to be exogenous.↩︎
- This approach provides an alternative to models that use broad age groups and exogenous migration flows (Brennan et al. 2020), creating flexibility for agents to remain within an age group for more/less time than is spanned by the age group.↩︎
- As this population does not contain any individuals aged 90 and above, these age groups are dropped.↩︎
References
AXTELL, R. (2000). Effects of interaction topology and activation regime in several multi-Agent systems. In S. Moss & P. Davidsson (Eds.), Multi-Agent-Based Simulation. Berlin Heidelberg: Springer. [doi:10.1007/3-540-44561-7_3]
AXTELL, R., Axelrod, R., Epstein, J. M., & Cohen, M. D. (1996). Aligning simulation models: A case study and results. Computational & Mathematical Organization Theory, 1, 123–141. [doi:10.1007/bf01299065]
AXTELL, R. L., & Epstein, J. M. (1999). Coordination in transient social networks: An agent-based computational model of the timing of retirement. In H. Aaron (Ed.), Behavioral Dimensions of Retirement Economics (pp. 146–174). Washington, DC: Brookings Institution. [doi:10.1515/9781400842872.146]
AXTELL, R. (1999). The emergence of firms in a population of agents. Working Paper, Santa Fe Institute, Santa Fe, NM
BILLARI, F. C., & Prskawetz, A. (2003). Agent-Based Computational Demography: Using Simulation to Improve Our Understanding of Demographic Behaviour. Berlin Heidelberg: Springer.
BORELLA, M., & Moscarola, F. C. (2010). Microsimulation of pension reforms: Behavioural versus nonbehavioural approach. Journal of Pension Economics & Finance, 9(4), 583–607. [doi:10.1017/s1474747209990163]
BRENNAN, A., Buckley, C., Vu, T. M., Probst, C., Nielsen, A., Bai, H., Broomhead, T., Greenfield, T., Kerr, W., Meier, P. S., Rehm, J., Shuper, P., Strong, M., & Purshouse, R. C. (2020). Introducing CASCADEPOP: An open-source sociodemographic simulation platform for US health policy appraisal. International Journal of Microsimulation, 13(2), 21. [doi:10.34196/ijm.00217]
CAI, L., Creedy, J., & Kalb, G. (2006). Accounting for population ageing in tax microsimulation modelling by survey reweighting. Australian Economic Papers, 45(1), 18–37. [doi:10.1111/j.1467-8454.2006.00275.x]
DIAZ, B. A., Fürnkranz-Prskawetz, A., Feichtinger, G., & Kappel, G. (2010). Agent based models on social interaction and demographic behaviour. Vienna University of Technology
FAIR, K. R., & Guerrero, O. A. (2023). Endogenous labour flow networks. arXiv preprint. Available at: https://arxiv.org/abs/2301.07979.
GOUDET, O., Kant, J.-D., & Ballot, G. (2017). WorkSim: A calibrated agent-Based model of the labor market accounting for workers’ stocks and gross flows. Computational Economics, 50(1), 21–68. [doi:10.1007/s10614-016-9577-0]
HUBERMAN, B. A., & Glance, N. S. (1993). Evolutionary games and computer simulations. Proceedings of the National Academy of Sciences, 90(16), 7716–7718. [doi:10.1073/pnas.90.16.7716]
KANTOROVICH, L. V. (1960). Mathematical methods of organizing and planning production. Management Science, 6(4), 366–422. [doi:10.1287/mnsc.6.4.366]
LEFKOVITCH, L. P. (1965). The study of population growth in organisms grouped by stages. Biometrics, 21(1), 1–18. [doi:10.2307/2528348]
LEOMBRUNI, R., & Richiardi, M. (2006). LABORsim: An agent-Based microsimulation of labour supply - An application to Italy. Computational Economics, 27(1), 63–88. [doi:10.1007/s10614-005-9016-0]
LESLIE, P. H. (1945). On the use of matrices in certain population mathematics. Biometrika, 33(3), 183–212. [doi:10.1093/biomet/33.3.183]
LESLIE, P. H. (1948). Some further notes on the use of matrices in population mathematics. Biometrika, 35(3–4), 213–245. [doi:10.1093/biomet/35.3-4.213]
NEUGART, M., & Richiardi, M. (2018). Agent-based models of the labor market. Publications of Darmstadt Technical University, Institute for Business Studies (BWL)
NOWAK, M. A., & May, R. M. (1992). Evolutionary games and spatial chaos. Nature, 359(6398), 826–829. [doi:10.1038/359826a0]
SCHINDLER, J. (2012). The importance of being accurate in agent-Based models - An illustration with agent aging. In I. J. Timm & C. Guttmann (Eds.), Multiagent System Technologies (pp. 165–177). Berlin Heidelberg: Springer. [doi:10.1007/978-3-642-33690-4_16]
UNITED Nations. (2019). World opulation prospects 2019, online edition. Department of Economic and Social Affairs, Population Division
VASERSTEIN, L. N. (1969). Markov processes over denumerable products of spaces, describing large systems of automata. Problemy Peredachi Informatsii, 5(3), 64–72.