
Juan de Lara and Manuel Alfonseca (2002)
The role of oblivion, memory size and spatial separation in dynamic language games
Journal of Artificial Societies and Social Simulation
vol. 5, no. 2
To cite articles published in the Journal of Artificial Societies and Social Simulation, please reference the above information and include paragraph numbers if necessary
<https://www.jasss.org/5/2/1.html>
Received: 3-Dec-2001 Accepted: 12-Mar-2002 Published: 31-Mar-2002
 Abstract
AbstractFor-all agent (a): a chooses a movement directionListing 1: pseudocode of the actions performed at each time step
For-all agent (a): a moves according to the chosen direction
For-all agent (a):
For-all agent (b) such that b is located in the same position as a
a dialogs with b about a's chosen direction
| Movement | 1st word and confidence | 2nd word and confidence | 3rd word and confidence | 4th word and confidence |
| N | (128, 4) | (300, 2) | (987, 6) | (0, 0) |
| S | (2, 7) | (30, 2) | (504, 1) | (300, 3) |
| E | (15, 2) | (0, 0) | (0, 0) | (0, 0) |
| W | (657, 5) | (226, 3) | (0, 0) | (0, 0) |
|
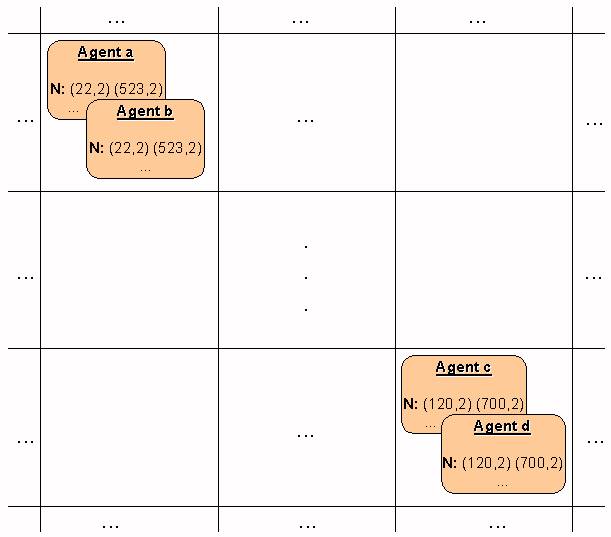
| Figure 1. Deadlock produced in a situation with no negative feedback (memory size=2) |
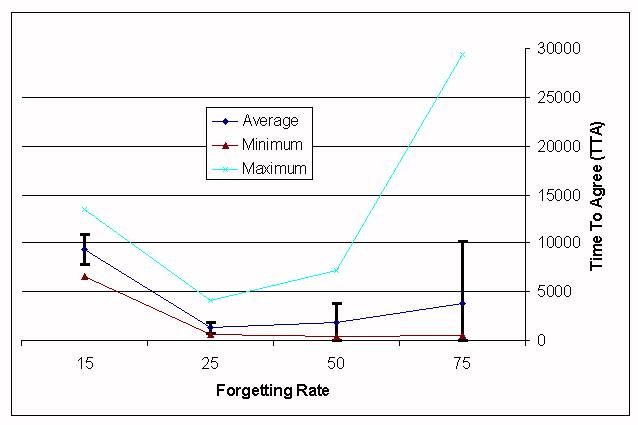
A problem with this approach is how to choose the appropriate forgetting rate. Figure 2 shows a comparison of different rates: 15, 25, 50, 75 with a memory size of 4. These are the intervals (number of time steps) at which the confidences are decreased. Each rate of forgetting was tested by 30 experiments. For rates less than 15 or greater than 75, the experiments never ended in 35000 time steps. The standard deviation is shown as error bars.
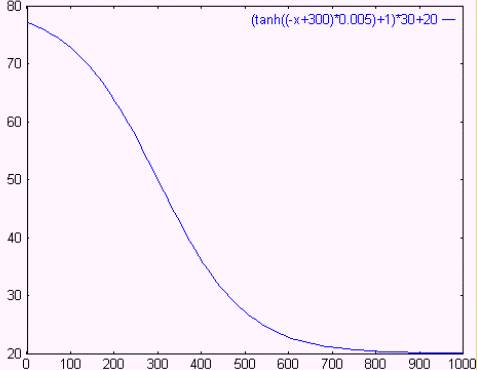
Looking at the graphic, it can be seen that the best fixed rate of forgetting is around 30. But, looking at the simulations, it can be observed that, for lower forgetting rates, convergence towards agreement accelerates in the final phase, whereas with higher forgetting rates the standard deviation decreases quickly at the beginning, but takes longer in the final time steps. This suggests it could be better to use a variable forgetting rate, in such a way that the agents forget slowly at the beginning, with the rate increasing as time goes by. For this purpose, we have used the hyperbolic-tangent time-dependent expression in figure 3 (where the x-axis is the time scale).
|
| Figure 2. TTA, depending on the forgetting rate |
|
| Figure 3. Expression used for the forgetting rate |
Using that expression, the agreement process is accelerated considerably. The following table shows a comparison with the fixed rate experiments.
| Fixed at 75 | Fixed at 50 | Fixed at 25 | Fixed at 15 | Variable | |
| Average | 3740.1 | 1858 | 1284.5 | 9324.47 | 873.74 |
| Standard Deviation | 6399.13 | 1921.51 | 595.11 | 1576.11 | 520.03 |
| Minimum | 552 | 450 | 660 | 6506 | 438 |
| Maximum | 29348 | 7180 | 4105 | 13498 | 2754 |
| Memory Size | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Average | 3327.9 | 649 | 669.5 | 875.4 | 1098.5 | 1396.5 | 1864.5 |
| Standard deviation | 4747.9 | 184.7 | 126 | 110.2 | 182 | 280.8 | 419.8 |
| Minimum | 530 | 406 | 497 | 695 | 792 | 1001 | 1224 |
| Maximum | >35000 | 1152 | 1033 | 1211 | 1525 | 2010 | 3222 |
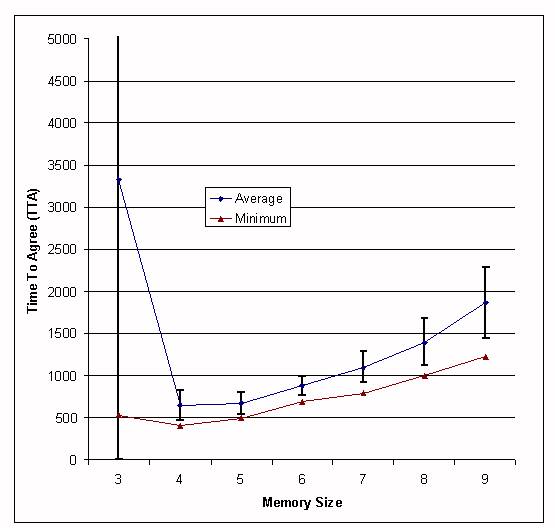
|
| Figure 4. TTA depending on the memory size, competition approach. |
| Memory Size | 2 | 3 | 4 | 5 |
| Average | 2223 | 1760.4 | 873.7 | 2026 |
| Standard deviation | 2409.9 | 1805.4 | 520 | 3653 |
| Minimum | 711 | 628 | 438 | 469 |
| Maximum | 9902 | 9001 | 2754 | 13971 |
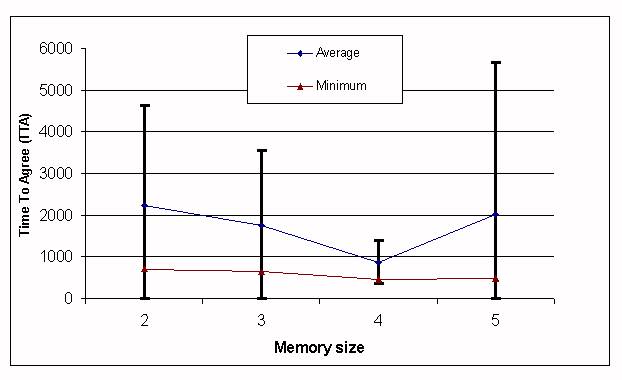
|
| Figure 5. TTA depending on the memory size, forgetting approach. |
| Memory Size | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Average | 787.3 | 705.6 | 597.6 | 673.5 | 949.2 | 1251.2 | 1767.5 | 2400 |
| Standard deviation | 167.3 | 264.9 | 163.2 | 135.6 | 186.5 | 256.8 | 440.3 | 591 |
| Minimum | 564 | 399 | 380 | 473 | 652 | 862 | 1013 | 1090 |
| Maximum | 1181 | 1390 | 1022 | 1210 | 1441 | 1933 | 3320 | 3673 |
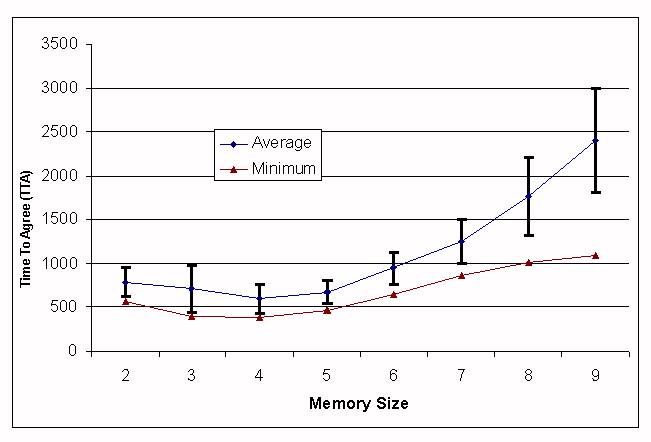
|
| Figure 6. TTA depending on the memory size, competition-forgetting approach. |
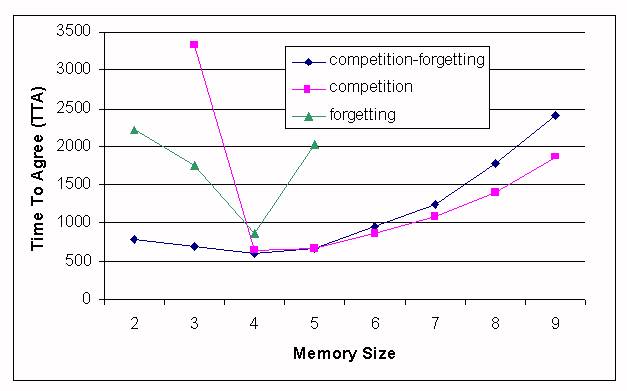
|
| Figure 7. Comparison of all the approaches |
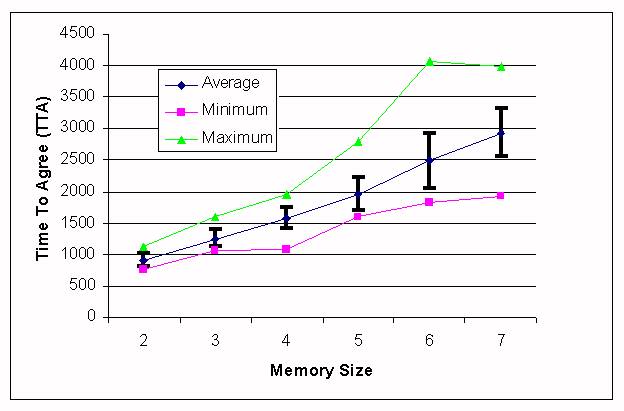
|
| Figure 8. TTA depending on the memory size, 8 concepts to be learned, competition-forgetting approach. |
| Population Density | 0.68 | 0.907 | 1.361 | 1.814 | 2.268 | 2.721 | 3.175 |
| Optimal memory Size | 2 | 3 | 4 | 4 | 5 | 6 | 6 |
| TTA | 803.57 | 651.17 | 597.57 | 579.97 | 551.6 | 587.37 | 595.57 |
| Standard deviation | 238.72 | 163.1 | 160.42 | 157.86 | 189.96 | 156.93 | 189.61 |
| Minimum | 443 | 475 | 380 | 320 | 293 | 416 | 323 |
| Maximum | 1431 | 1244 | 1022 | 1052 | 1053 | 1143 | 1142 |
Px,y (0) = ((M-1)/M)N
Px,y(1) = (N/M)*((M-1)/M)N-1
Px,y(DLG)=1-(Px,y(0)+Px,y(1))because at least two agents are needed for a DLG to take place. Figure 9 shows these probabilities with respect to the agent population density (number of agents divided by the number of positions in the grid).
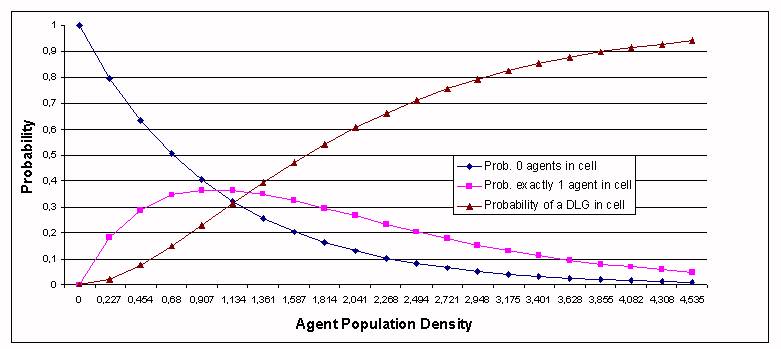
|
| Figure 9. Probability of a DLG in a particular cell as a function of the agent population density. |
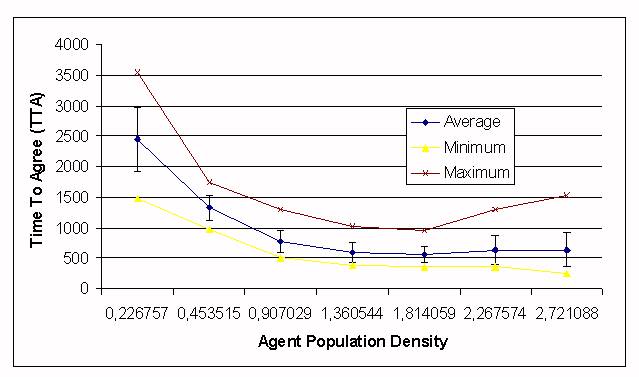
|
| Figure 10. TTA depending on the number of agents in the simulation, competition-forgetting approach. |
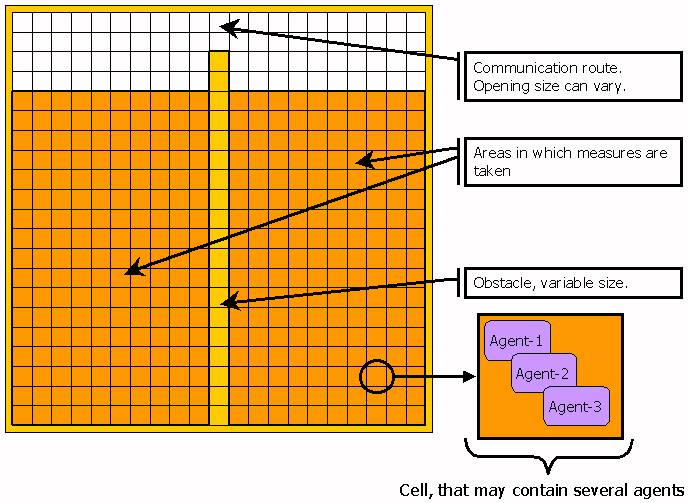
|
| Figure 11. Configuration of the experiments with spatial separation |
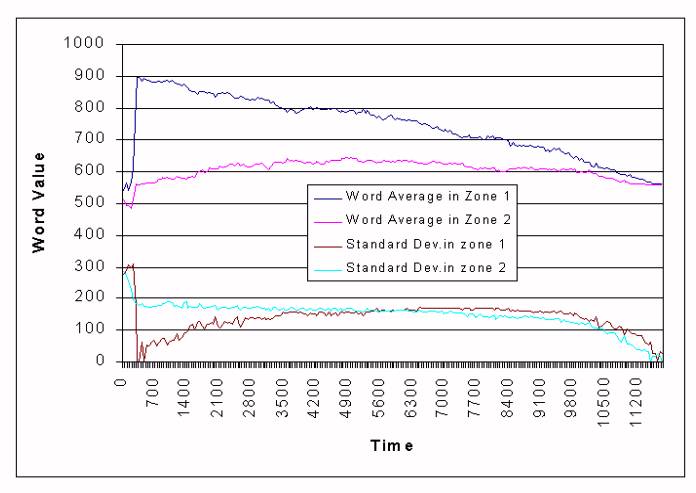
|
| Figure 12. Evolution of the word for "West" in a population divided in two zones. |
BAILLIE, J, NEHANIV, C., "Deixis and the Development of Naming in Asynchronously Interacting Connectionist Agents", Proceedings of the First International Workshop on Epigenetic Robotics, Lund University. Cognitive Studies, vol. 85, pp. 123-129, 2001.
BILLARD, A., DAUTENHAHN, K. "Experiments in Learning by Imitation - Grounding and Use of Communication in Robotic Agents", Adaptive Behavior. 1999, 7(3), 411-434.
DAWKINS, R. 1976. "The Selfish Gene". New York, Oxford University Press.
de LARA, J., ALFONSECA, M. 2000. "Some strategies for the simulation of vocabulary agreement in multi-agent communities". Journal of Artificial Societies and Social Simulation vol. 3, no. 4, <https://www.jasss.org/3/4/2.html>.
FYFE, C., Livingstone, D. 1997. "Developing a Community Language". ECAL¥97, Brighton, UK.
HURFORD, J. 1999. "Language Learning from Fragmentary Input". In Proceedings of the AISB'99 Symposium on Imitation in Animals and Artifacts. Society for the Study of Artificial Intelligence and Simulation of behavior. pp.121-129.
KIRBY, S. 1998. "Language evolution without natural selection: From vocabulary to syntax in a population of learners"'. Edinburgh Occasional Paper in Linguistics EOPL-98-1.
NEHANIV, C.L. 2000. "The Making of Meaning in Societies: Semiotic & Information-Theoretic Background to the Evolution of Communication". In Proceedings of the AISB Symposium: Starting from society - the application of social analogies to computational systems. pp. 73-84.
OLIPHANT, M. 1996. "The Dilemma of Saussurean Communication". BioSystems, 37(1-2), pp. 31-38.
OLIPHANT, M., BATALI, J. 1996. "Learning and the Emergence of Coordinated Communication". Center for Research on Language Newsletter 11(1).
STEELS, L. 1996a. "Self-organizing vocabularies". In C. Langton, editor. Proceedings of Alife V, Nara, Japan. 1996.
STEELS, L. 1996b. "A self-organizing spatial vocabulary". Artificial Life Journal. 2(3) 1996.
STEELS, L. 1998a. "The Origins of Ontologies and Communication Conventions in Multi-Agents Systems". Autonomous Agents and Multi-Agents Systems, 1, 169-194. STEELS, L, KAPLAN, F. 1998b. "Spontaneous Lexicon Change". In COLING-ACL98, pages 1243--1249. ACL, Montreal, 1998.
WITTGENSTEIN, L. 1974. "Philosophical Investigations". Basil Blackwell, Oxford.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2002]