
Laurie Brown and Ann Harding (2002)
Social Modelling and Public Policy: Application of Microsimulation Modelling in Australia
Journal of Artificial Societies and Social Simulation
vol. 5, no. 4
To cite articles published in the Journal of Artificial Societies and Social Simulation, please reference the above information and include paragraph numbers if necessary
<https://www.jasss.org/5/4/6.html>
Received: 28-Sep-2002 Published: 31-Oct-2002
 Abstract
AbstractDynamically ageing microsimulation models, on the other hand, involves updating each attribute for each micro-unit for each time interval. Dynamic models are more complicated in that a temporal element is introduced into the modelling. Individuals are aged and stochastically undergo transitions, as well as being subject to modified policy regimes (Halpin 1999; Sauerbier 2002). Dynamic models often start from exactly the same cross-section sample surveys as static models. However, the individuals within the original microdata (the model's cohort) are then progressively moved forward through time. This is achieved by making major life events - such as education and training, labour force participation, family formation and dissolution (marriage, children, separation, divorce), migration, retirement, death etc - happen to each individual, in accordance with the probabilities of such events happening to real people within a particular country. Thus, within a dynamic microsimulation model, the characteristics of each individual are recalculated for each time period. This involves the use of large transition matrices or econometric techniques to determine the various year-to-year shifts. Hence, dynamic microsimulation models are generally much more complex and expensive to build.
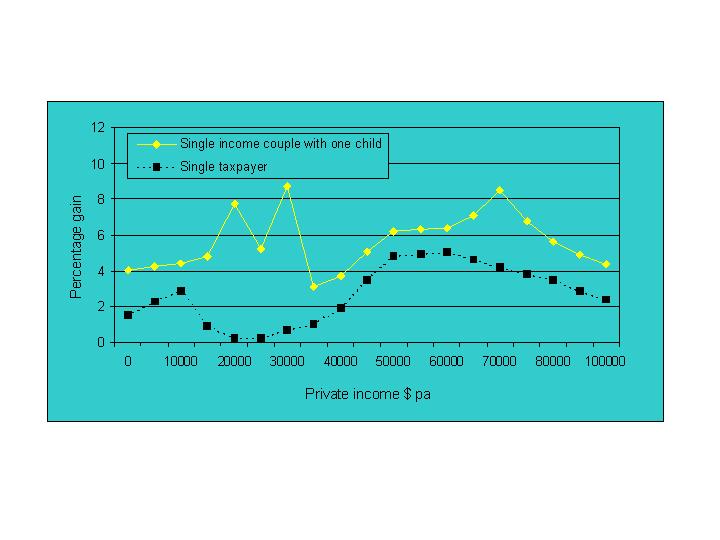
|
| Figure 1. Estimated Percentage Gain in Disposable Income from the Final GST Tax Reform Package (Source: Harding et al 2000) |
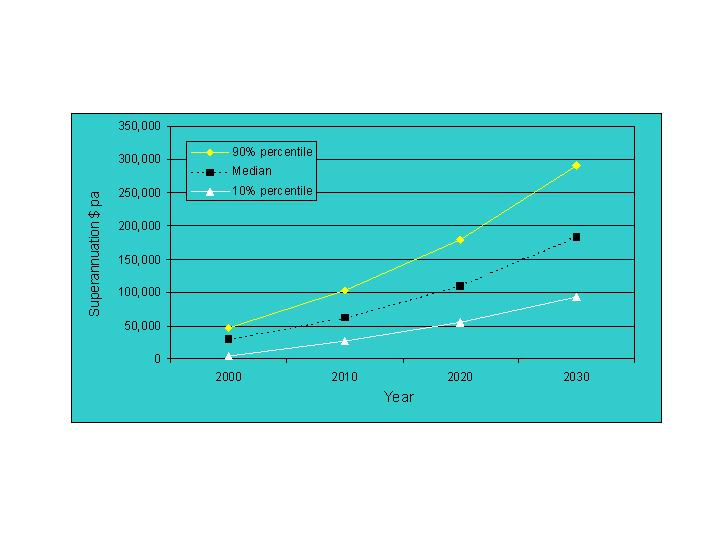
|
| Figure 2. Forecast Superannuation Assets for Women Aged 55 to 64 Years, 2000 to 2030 (Source: Kelly et al. 2001) |
2 Newstart is for unemployed people aged over 21 or people who are temporarily unable to work due to illness, injury or disability.
3 The APMA Model basefile excludes persons (and their families) that have no expenditure on prescribed drugs, and persons living in institutionalised care, for example, hospitals or nursing homes. Prescribed drug usage figures at ages above 70 years, therefore, are likely to be under-estimates.
ACT Chief Minister's Department, Australian Capital Territory Government (2002). Youth in the ACT.A social and demographic profile. ACT Government, Canberra.
BALLAS, D and Clarke G. (1999). 'Modelling the local impacts of national social policies: A microsimulation approach', Papers presented at the 11th European Colloquium on Theoretical and Quantitative Geography, Durham Castle, Durham, England, 3rd to 7th September, 1999.
BREMNER, K., Beer, G., Lloyd, R., and Lambert, S. (2002). Creating a Basefile for STINMOD, NATSEM Technical Paper No. 27, University of Canberra, Canberra.
CALDWELL, S. B., Clarke, G. P. and Keister, L.A. (1998). Modelling Regional Changes in US Household Income and Wealth: A Research Agenda, Environment and Planning C: Government and Policy, 16, pp. 707-722.
CITRO, C.F. and Hanushek, E.A. (1991). The Uses of Microsimulation Modelling, Review and Recommendations, Vol 1, National Academy Press, Washington.
COMAREN P, Ventcatasawmy, Holm, E., Rephann, T., Esko, J., Swan,N., Ohman, M., Astrom, M., Alfredson, E., Holme K., and Siikavaara, J. (1999). 'Building a spatial microsimulation model', Spatial Modelling Centre on Human Dimension of Environmental Change, SMC, Urnea Universtiy and Lulea Technical University, Kiruna Sweden. Paper presented at the 11th European Collopuium on Quantatative and Theoretical Geography, Durham England, Sept. 1999.
CONSIDINE, M. (1994). Public Policy: a Critical Approach. MacMillan, South Melbourne.
CREEDY, J. (2001). Tax modelling. Economic Record, 77 (237), pp. 189-202.
GREGORY, R.G. and B. Hunter. (1995). The macro economy and the growth of ghettos and urban poverty in Australia. Discussion Paper No 325, Centre for Economic Policy Research, Australian National University.
GUPTA, A. and Kapur, V. (eds) (2000). Microsimulation in Government Policy and Forecasting, Contributions to Economic Analysis Series, North Holland, Amsterdam.
HALPIN, B. (1999). Simulations in sociology. The American Behavioral Scientist. 42(10), pp.1488-1508.
HARDING, A. (ed). (1996). Microsimulation and Public Policy, Contributions to Economic Analysis Series, Amsterdam, North Holland.
HARDING, A. and Szukalska, A. (2000).Trends in Child Poverty in Australia, 1982 to 1995-96, Economic Record, 96(234), pp. 236-254.
HARDING, A., Lloyd, R., Hellwig, O. and Bailey, G. (2000). Building the Profile: Report of the Population Research Phase of the ACT Poverty Project, Poverty Task Group Paper No. 3, ACT Government, Canberra.
KELLY, S., Percival, R. and Harding, A. (2001). Women and Superannuation in the 21st Century: Poverty or Plenty? Paper presented at the National Social Policy SPRC Conference, University of New South Wales, Sydney, Australia. 4-6 July 2001.
KING, A., Bækgaard, H. and Robinson, M. (1999). Dynamod-2: An Overview.Technical Paper No. 19, National Centre for Economic Modelling, University of Canberra.
LLOYD, R., Harding, A. and Greenwell, H. (2002). Worlds Apart: Postcodes with the Highest and Lowest Poverty Rates in Today's Australia, in Eardley, A., and Bradbury, B. (eds), Refereed Proceedings of the National Social Policy Conference 2001, SPRC Report 1/02, April. 2002.
MARCH, J.G. and Olsen, J.P. (1989). Rediscovering Institutions: The Organisational Basis of Politics. The Free Press, New York.
MURPHY, P. and Watson, S. (1997). Surface City: Sydney at the Millennium. Pluto Press, Sydney.
OECD, (1996). Policy Implications of Ageing Populations: Introduction and Overview, OECD Working Paper no. 33, Paris.
ORCUTT, G. (1957). A new type of socio-economic system, Review of Economics and Statistics, 58(2), pp. 773-797.
ORCUTT, G., Greenberger, M., Korbel J. and Rivlin, A. (1961). Microanalytic Simulation Models to Support Social and Financial Policy, Harper and Row, New York.
SAUERBIER, T. (2002). UMDBS - A new tool for dynamic microsimulation. JASSS, 5 (2), https://www.jasss.org/5/2/5.html
TAYLOR, R., Quine, S., Lyle, D., and Bilton, A. (1992). Socioeconomic correlates of mortality and hospital morbidity differentials by Local Government Area in Sydney 1985-1988. Australian Journal of Public Health, 16(3), pp. 305-314.
VOAS, D and Williamson, P. (2000). An Evaluation of the Combinatorial Optimisation Approach to the Creation of Synthetic Microdata, International Journal of Population Geography, 6, pp. 348-366.
VINSON, T. (1999). Unequal in Life: The Distribution of Social Disadvantage in Victoria and NSW, The Ignatius Centre, Melbourne.
WALKER, A. and Abello, A. (2000). Changes in the Health Status of Low Income Groups in Australia, 1977-78 to 1995, Discussion Paper 52, National Centre for Economic Modelling, University of Canberra.
WALKER, A. (1999). Distributional Impact of Higher Patient Contributions to Australia's Pharmaceutical Benefits Scheme . Discussion Paper no. 45, National Centre for Economic Modelling, University of Canberra, September, 1999.
WALKER, A., Percival, R. and Fischer, SA. (1998). Microsimulation Model of Australia's Pharmaceutical Benefits Scheme -Technical Paper No. 15, National Centre for Economic Modelling, University of Canberra . August, 1998.
WARREN, N., Harding, A., Robinson, M., Lambert, S. and Beer, G. (1999). Distributional Impact of Possible Tax Reform Packages, Main Report, Senate Select Committee on a New Tax System, Senate Printing Unit, 445-508, 1999.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2002]