
A. O. I. Hoffmann, W. Jager and J. H. Von Eije (2007)
Social Simulation of Stock Markets: Taking It to the Next Level
Journal of Artificial Societies and Social Simulation
vol. 10, no. 2, 7
<https://www.jasss.org/10/2/7.html>
For information about citing this article, click here
Received: 01-May-2006 Accepted: 09-Jan-2007 Published: 31-Mar-2007

 Abstract
Abstractthere still is a gap to be bridged between the individual investor and the market, and the question of aggregation has not been settled yet. (Van der Sar 2004: 442)
|
If |
(1) |
|
If |
(2) |
|
If |
(3) |
Est = Expected price for stock s at time t
Pst = Current market price for stock s at time t
That is, an agent weighs the deviation of the current market price from the expected price for the next period by the current market price. When the expected price is higher than the current price it is attractive to invest, when the expected price is lower than the current price, it is more attractive to divest. The agents react stronger as the expected price deviates more from the current market price.[3] Depending on the standard deviation that is chosen for the news, it would be possible that the above formula returns values that would imply an agent to invest more than its current cash budget allows or to sell more stocks than it has in portfolio. In these instances — of which the chances of occurring are extremely small using the parameter settings of the experiments that are discussed in this paper — the proportion is limited to the agent's available cash budget and portfolio of shares as can be seen in the formula's above. So, investors are not allowed to borrow money or short-sell stocks.
| Table 1: Risk reducing strategies | ||
| Individual | Social | |
| Simplifying | Use a simple heuristic, e.g., the P/E ratio of a stock. | Copy the behaviour of other investors in one's social network. |
| Clarifying | Collect more information about the stock. | Ask other investors for more information, e.g., their expectations of the stock value. |
|
If |
(4) |
|
If |
(5) |
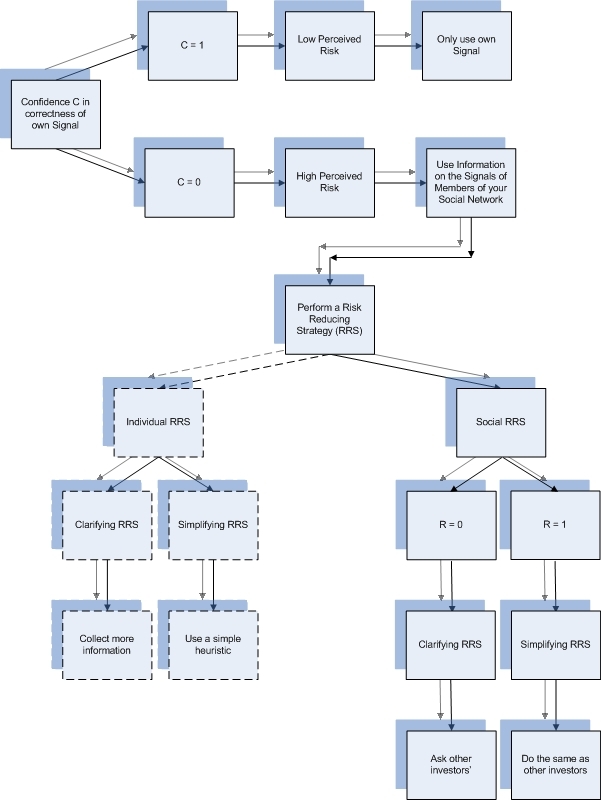
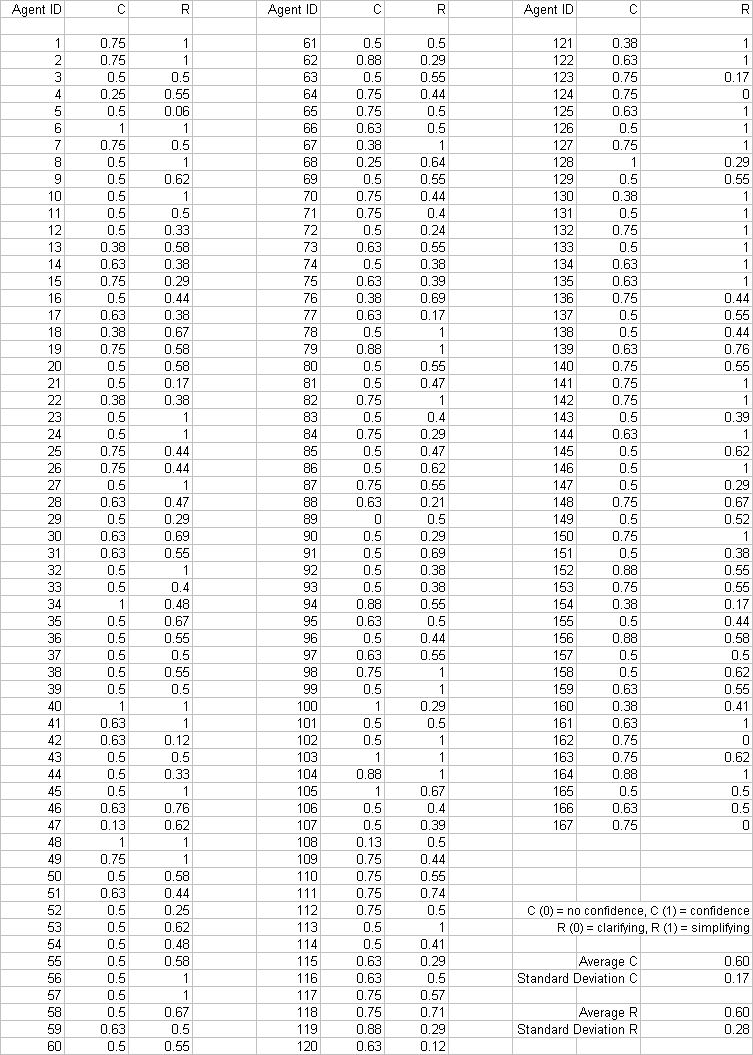
These three steps resulted in an empirically validated set of estimates of R for a group of 167 investors. A schematical overview of the above is given in figure 1 below. Although in this overview, only the extreme situations (C = 0, C = 1, R = 0, R = 1) are displayed, investors in our model can also trust partly on their own signal and partly on information obtained from their social network (0 < C < 1) and use a combination of both clarifying and simplifying strategies (0 < R < 1) as can be seen in appendix 3.
|
| Figure 1. Simplified overview of the SSE agents' trading behaviour |
|
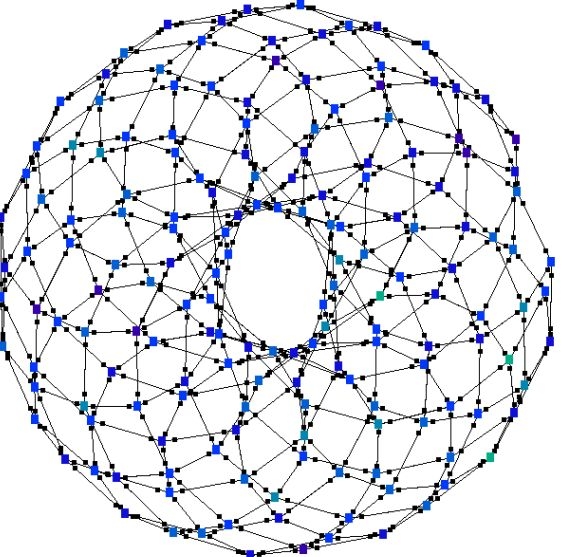
| Figure 2. Torus network |
|
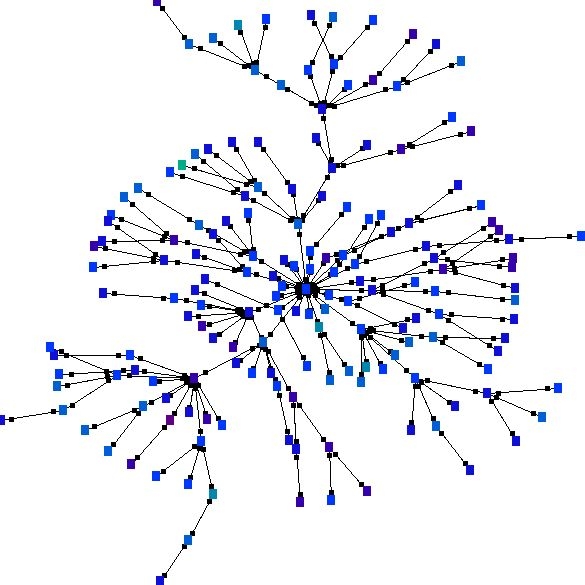
| Figure 3. Barabasi and Albert scale free network |
| Table 2: General parameter settings | ||
| Parameter description | Experiment 1 | Experiment 2 |
| Number of agents | 167 | 167 |
| Initial wealth of agents | 100 | 100 |
| Bankrupt agents | Are replaced | Are replaced |
| Network type | Torus | Scale free network |
| News distribution | Normal | Normal |
| News average μ | 0 | 0 |
| News standard deviation σ | 0.020 | 0.020 |
| News frequency | Every time step | Every time step |
| Number of stocks | 1 | 1 |
| Number of time steps | 929 | 929 |
| Initial number of stocks in portfolio | 10 | 10 |
| Initial stock price | 10 | 10 |
| Updating of confidence of agents according to their returns | Yes | Yes |
| Level of confidence C | See appendix 3 | See appendix 3 |
| Risk Reducing Strategy R | See appendix 3 | See appendix 3 |
| Seed to generate network | 1159791325531 | 1159791325531 |
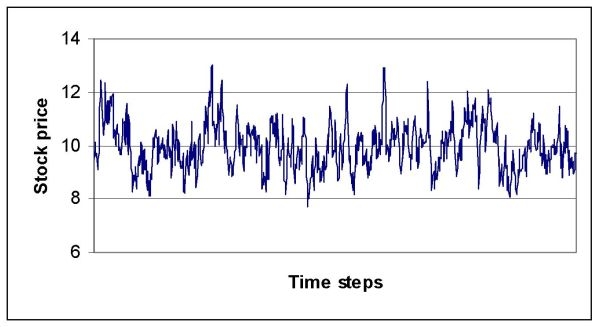
|
| Figure 4. Price time series experiment 1 (torus network) |
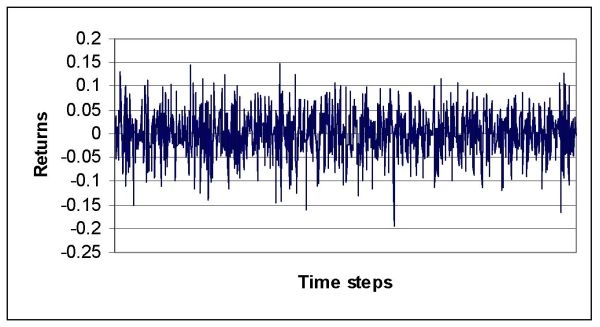
|
| Figure 5. Returns time series experiment 1 (torus network) |
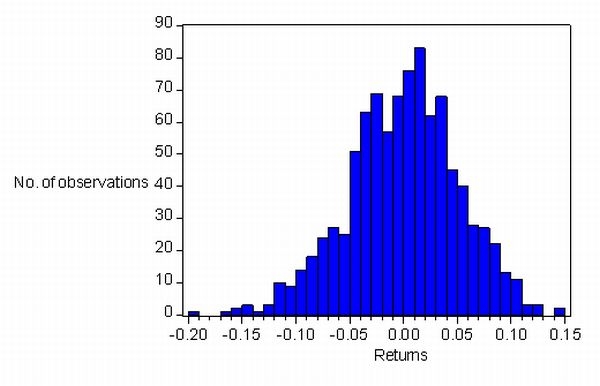
|
| Figure 6. Returns distribution experiment 1 (torus network) |
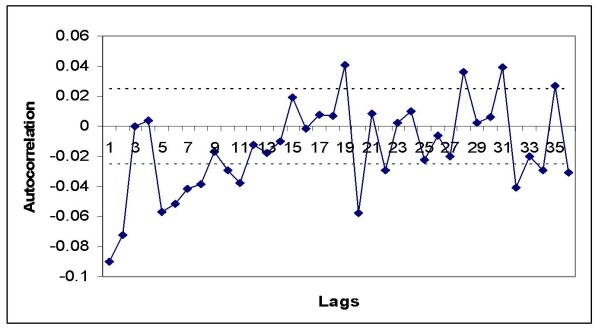
|
| Figure 7. Autocorrelation graph of the returns of experiment 1 (torus network) |
|
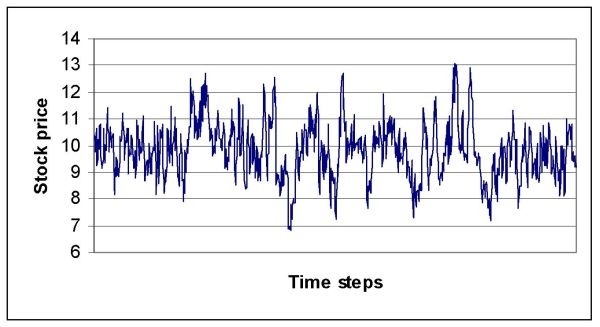
| Figure 8. Price time series experiment 2 (scale free network) |
|
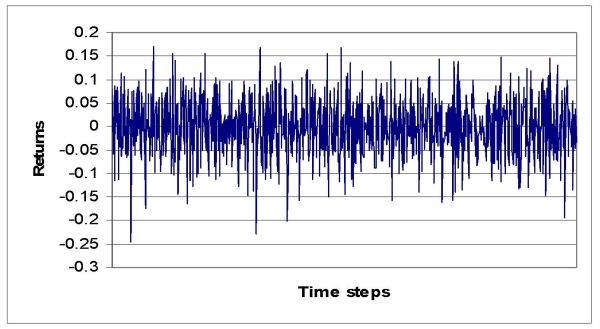
| Figure 9. Returns time series experiment 2 (scale free network) |
|
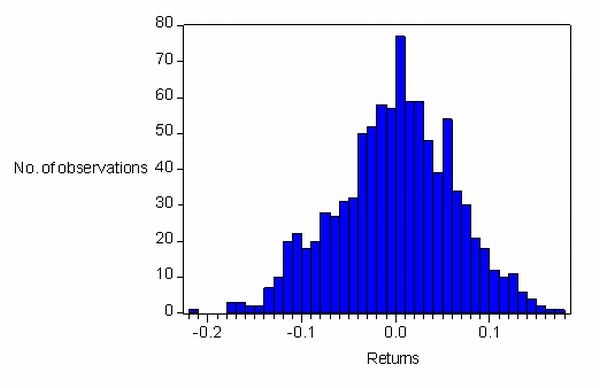
| Figure 10. Returns distribution experiment 2 (scale free network) |
|
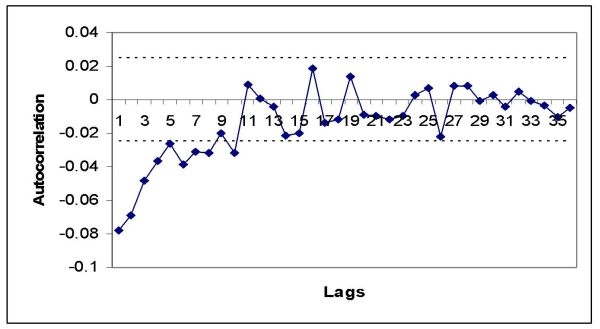
| Figure 11. Autocorrelation graph of the returns of experiment 2 (scale free network) |
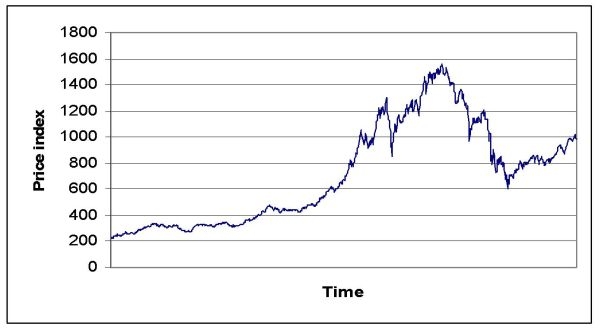
|
| Figure 12. Price index time series overall Dutch stock market 1987~2005 |
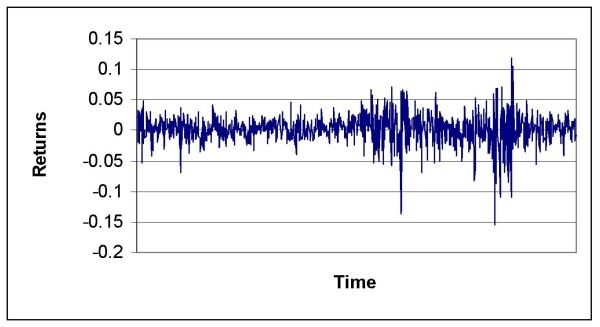
|
| Figure 13. Returns time series overall Dutch stock market 1987~2005 |
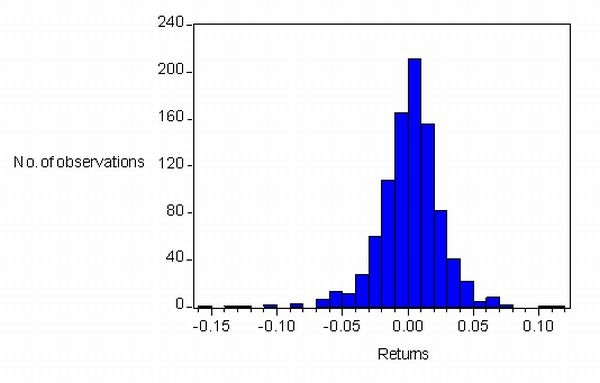
|
| Figure 14. Returns distribution overall Dutch stock market 1987~2005 |
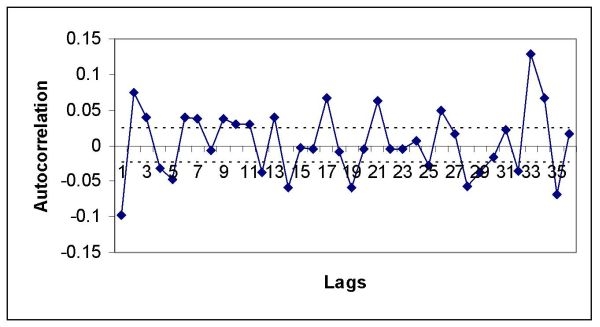
|
| Figure 15. Autocorrelation graph of the returns of the overall Dutch stock market 1987~2005 |
| Table 3: Summary statistics of experiment 1, 2, and the overall Dutch stock market | ||||||
| Description | Experiment 1: torus network | Experiment 2: scale free network | Dutch Stock Market | |||
| Std. σ | 0.051 | 0.063 | 0.025 | |||
| Kurtosis | 3.149 | 2.919 | 8.466 | |||
| Durbin Watson Statistic | 2.184 | 2.117 | 2.194 | |||
| Coeff. | Prob. | Coeff. | Prob. | Coeff. | Prob. | |
| Jarque-Bera | 7.795** | 0.020 | 4.819 | 0.090 | 1262.518* | 0.000 |
| Conditional Variance Equation | ||||||
| Experiment 1: torus network | Experiment 2: scale free network | Dutch Stock Market | ||||
| Coeff. | Prob. | Coeff. | Prob. | Coeff. | Prob. | |
| C | 0.000 | 0.9000 | 0.001 | 0.718 | 0.002* | 0.000 |
| Residuals (-1)^2 (ARCH) | 0.015 | 0.511 | 0.061 | 0.156 | 0.148* | 0.000 |
| GARCH (-1) | 0.827* | 0.004 | 0.078 | 0.895 | 0.828* | 0.000 |
| ||||||
2 In the current formalization of the SSE, the latter characteristic implies that the market interactions are a zero-sum game. Furthermore, the current formalization of the SSE features no transaction costs.
3 This mechanism can be interpreted as a form of symmetrical, linear loss aversion and is comparable to the mechanisms used in e.g. , Day and Huang (1990). It is also possible to include a more elaborate loss aversion mechanism, like the type as assumed in the prospect theory (Kahneman & Tversky 1979). Asymmetrical loss aversion types, however, call for more elaborate methods of analysis that take this asymmetry into account, like EGARCH (Brooks 2004). For an example of the application of a loss aversion mechanism as proposed by prospect theory, see e.g., Takahashi and Terano (2003).
4 The SSE also offers other options of weighting the expectations of the agents' neighbors, like weighting the neighbors' expectations according to the importance of their network position or their past success in investing. These options, however, are until now not researched and outside the scope of this paper.
5 We use the in the financial literature common phrase “crossing of orders” to indicate, that a buy or sell order matches another sell or buy order, respectively, and subsequently a transaction takes place.
6As the 167 investors for which we have obtained empirical data do not constitute a social network by themselves, but rather are a sample of the overall Dutch investor population, the exact positions of the investor agents in the two different social networks is arbitrarily chosen. In future research, one might try to rebuild an existing social network of investors and incorporate it in an artificial stock market. We have also performed the same simulation experiments, but then creating 10 copies or “clones” of the 167 agents, resulting in 1670 agents, in order to test for the occurrence of the law of large numbers. However, the results of these experiments are exactly the same as those of the experiments with only 167 agents
7 This was the longest time frame available from DataStream at the time of collecting the data for this article (October 2005).
8 Autocorrelation is the correlation of a process Xt against a time-shifted version of itself. The efficient markets hypothesis of modern finance literature assumes that the residuals of today are uncorrelated with the residuals of tomorrow. That is, today's news is completely and immediately absorbed in today's stock prices and has no effect on tomorrow's stock prices. When the Durbin Watson statistic takes on the test value of two, this corresponds to the case where there is no autocorrelation in the residuals. When this statistic takes on a test value of zero, this corresponds to the case of perfect positive autocorrelation in the residuals. In case the test statistic takes on the value of four, this corresponds to the case where there is perfect negative autocorrelation in the residuals.
9 ARCH is the test for conditional heteroscedasticity as developed by Engle (1982). GARCH is a generalized model for conditional heteroscedasticity as developed independently by Bollerslev (1986) and Taylor (1986).
10 We thank one of the anonymous referees for bringing this issue to our attention.
ARIFOVIC, J. (1996). The behavior of the exchange rate in the genetic algorithm and experimental economies. Journal of Political Economy, 104, 510-541.
ARTHUR, W. B. (1995). Complexity in Economic and Financial Markets. Journal of Complexity, 1.
ARTHUR, W. B., Holland, J., LeBaron, B., & Palmer, R. T. P. (1997). Asset pricing under endogenous expectations in an artificial stock market. In W.B.Arthur, S. Durlauf, & D. Lane (Eds.), The economy as an evolving complex system II (pp. 15-44). Reading, MA: Addison-Wesley.
AXELROD, R. (1997). The Complexity of Cooperation. Princeton: Princeton University Press.
AXTELL, R. L. (2000). Why Agents? On The Varied Motivations For Agent Computing In The Social Sciences. (Rep. No. 17).
BARABASI, A.-L. (2002). Linked. The new science of networks. Cambridge, Massachusetts: Perseus Publishing.
BARABASI, A.-L. & Albert, R. (1999). Emergence of scaling in random networks. Science, 286, 509-512.
BELTRATTI, A. & Margarita, S. (1992). Evolution of trading strategies among heterogeneous artificial economic agents. In J.A.Meyer, H. L. Roitblat, & S. W. Wilson (Eds.), From animals to animats 2. Cambridge, MA: MIT Press.
BERA, A. K. & Jarque, C. M. (1981). Efficient tests for normality, homoskedasticity and serial independence of regression residuals: Monte Carlo evidence. Economics Letters, 7, 313-318.
BERA, A. K. & Jarque, C. M. (1980). Efficient tests for normality, homoskedasticity and serial independence of regression residuals. Economics Letters, 6, 255-259.
BERNARD, V. L. & Thomas, J. K. (1989). Post-Earnings-Announcement Drift: Delayed Price Response or Risk Premium? Journal of Accounting Research, 27, 1-36.
BIKHCHANDANI, S., Hirschleifer, D., & Welch, I. (1998). Learning from the behavior of others: conformity, fads, and informational cascades. Journal of economic perspectives, 12, 151-170.
BOLLERSLEV, T. (1986). Generalised Autoregressive Conditional Heteroskedasticity. Journal of Econometrics, 31, 307-327.
BRAY, M. (1982). Learning, estimation, and the stability of rational expectations. Journal of economic theory, 26, 318-339.
BROOKS, C. (2004). Introductory Econometrics for Finance. Cambridge: Cambridge University Press.
BUCHANAN, M. (2002). Small World: uncovering nature's hidden networks. London: Phoenix.
BURNKRANT, R. E. & Cousineau, A. (1975). Informational and Normative Social Influence in Buyer Behavior. The Journal of Consumer Research, 2, 206-215.
CHEN, S.-H., Lux, T., & Marchesi, M. (2001). Testing for Non-Linear Structure in an Artificial Financial Market. Journal of Economic Behavior and Organization, 46, 327-342.
CHIARELLA, C. (1992). The dynamics of speculative behavior. Annals of Operations Research, 37, 101-123.
CIALDINI, R. B. & Goldstein, N. J. (2004). Social Influence: Compliance and Conformity. Annual Review of Psychology, 55, 591-621.
CIALDINI, R. B. & Trost, M. R. (1998). Social influence: social norms, conformity, and compliance. In D.T.Gilbert, S. T. Fiske, & G. Lindzey (Eds.), The Handbook of Social Psychology (4 ed., pp. 151-192). Boston: McGraw-Hill.
CONT, R. (2001). Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance, 1, 223-236.
COWAN, R. & Jonard, N. (2004). Network structure and the diffusion of knowledge. Journal of Economic Dynamics and Control, 28, 1557-1575.
DAY, R. H. & Huang, W. (1990). Bulls, bears and market sheep. Journal of Economic Behavior and Organization, 14, 299-329.
DE BONDT, W. F. M. (1998). A portrait of the individual investor. European economic review, 42, 831-844.
DEUTSCH, M. & Gerard, H. B. (1955). A study of normative and informative social influences upon individual judgment. Journal of Abnormal and Social Psychology, 51, 629-636.
ENGLE, R. F. (1982). Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica, 50, 987-1007.
FAMA, E. F. (1970). Efficient capital markets: a review of theory and empirical work. Journal of finance, 25, 383-417.
FAMA, E. F. (1991). Efficient capital markets: II. Journal of finance, 46, 1575-1617.
FAMA, E. F., Fisher, K. L., Jensen, M. C., & Roll, R. (1969). The Adjustment of Stock Prices to New Information. International Economic Review, 10, 1-21.
GILBERT, N. & Troitzsch, K. G. (1999). Simulation for the Social Scientist. Buckingham: Open University Press.
GODE, D. K. & Sunder, S. (1993). Allocative efficiency of markets with zero intelligence traders. Journal of Political Economy, 101, 119-137.
GROSSMAN, S. & Stiglitz, J. (1980). On the impossibility of informationally efficient markets. American Economic Review, 70, 393-408.
HOFFMANN, A. O. I., Von Eije, J. H., & Jager, W. (2006). Individual Investors' Needs and Conformity Behavior: An Empirical Investigation. SSRN Working Paper Series. http://papers.ssrn.com/sol3/papers.cfm?abstract_id=835426 .
HOMMES, C. H. (2006). Interacting Agents in Finance. In L.Blume & S. Durlauf (Eds.), New Palgrave Dictionary of Economics (2nd ed.). Palgrave Macmillan.
KAHNEMAN, D. & Tversky, A. (1979). Prospect theory: an analysis of decision under risk. Econometrica, 47, 263-291.
KARAKEN, J. & Wallace, N. (1981). On the indeterminacy of equilibrium exchange rates. Quarterly journal of economics, 96, 207-222.
KEOWN, A. & Pinkerton, J. (1981). Merger Announcements and Insider Trading Activity. Journal of finance, 36, 855-869.
KIRMAN, A. P. (1992). Whom or What Does the Representative Individual Represent. Journal of economic perspectives, 6, 117-136.
KNIGHT, F. H. (1921). Risk, Uncertainty and Profit. Boston, MA : Hart, Schaffner & Marx; Houghton Mifflin Company.
LEBARON, B. (2000). Agent-based computational finance: suggested readings and early research. Journal of Economic Dynamics and Control, 24, 679-702.
LEBARON, B. (2005). Agent-based Computational Finance. In K.L.Judd & L. Tesfatsion (Eds.), The Handbook of Computational Economics, Vol. II North-Holland.
LEBARON, B., Arthur, W. B., & Palmer, R. (1999). Time series properties of an artificial stock market. Journal of Economic Dynamics and Control, 23, 1487-1516.
LETTAU, M. (1997). Explaining the facts with adaptive agents: the case of mutual fund flows. Journal of Economic Dynamics and Control, 21, 1117-1148.
LUX, T. (1998). The socio-economic dynamics of speculative markets: interacting agents, chaos, and the fat tails of return distributions. Journal of Economic Behavior and Organization, 33, 143-165.
LUX, T. (2006). Communication on the Artificial Economics 2006 Conference, Aalborg, Denmark. personal communication with the authors.
MASLOW, A. H. (1954). Motivation and personality. New York: Harper and Row.
MAX-NEEF, M. (1992). Development and Human Needs. In P.Ekins & M. Max-Neef (Eds.), Real-life economics: understanding wealth creation London/New York: Routledge.
MITCHELL, V.-W. & McGoldrick, P. J. (1996). Consumers' risk reducing strategies: a review and synthesis. The international review of retail, distribution and consumer research, 6, 1-33.
MITCHELL, V.-W. (1999). Consumer Perceived Risk: Conceptualisations and Models. European Journal of Marketing, 33, 163-195.
NEWMAN, M. E. J. (1999). Small Worlds. The structure of social networks. Santa Fe Institute Working Paper .
NOFSINGER, J. R. (2002). The psychology of investing. Upper Saddle River, New Jersey: Prentice Hall.
OLSEN, R. A. (1998). Behavioral finance and its implications for stock-price volatility. Financial Analysts Journal, March/April, 10-18.
PAGAN, A. (1996). The econometrics of financial markets. Journal of empirical finance, 3, 15-102.
ROUTLEDGE, B. R. (1994). Artificial selection: genetic algorithms and learning in a rational expectations model (Rep. No. Technical raport, GSIA). Carnegie Mellon, Pittsburgh, Penn.
SCHLEIFER, A. (2000). Inefficient markets, an introduction to behavioral finance. Oxford University Press.
SHEFRIN, H. (2002). Beyond greed and fear. Understanding behavioral finance and the psychology of investing. Oxford University Press.
TAKAHASHI, H. & Terano, T. (2003). Agent-Based Approach to Investors' Behavior and Asset Price Fluctuation in Financial Markets. Journal of artificial societies and social simulation, 6(3) https://www.jasss.org/6/3/3.html.
TAYLOR, J. W. (1974). The Role of Risk in Consumer Behavior. Journal of Marketing, 38, 413-418.
TAYLOR, S. J. (1986). Forecasting the Volatility of Currency Exchange Rates. International Journal of Forecasting, 3, 159-170.
TVERSKY, A. & Kahneman, D. (1974). Judgement under uncertainty: Heuristics and Biases. Science, 185.
VAN DER SAR, N. L. (2004). Behavioral finance: How matters stand. Journal of Economic Psychology, 25, 425-444.
VEB (2002). Is beleggen uit en sparen in? Effect, 5.
WATTS, A. and Strogatz, S. H. (1998, June). Collective dynamics of 'small-world' networks. Nature, 393, 440-442.
WELLMAN, B. & Berkowitz, S. D. (1997). Social Structures: a Network Approach. London: JAI Press.
| Est | = Expected price for stock s at time t |
| Pst | = Market price for stock s at time t |
| Nst | = News for stock s at time t |
| Strat | = Preference for an agent for simplifying risk reduction (0 ≤ Strat ≤ 1) |
| NEst | = Aggregated expected price for stock s at time t from an agents neighbours |
| SimplNEst | = Aggregated expected price for stock s at time t from an agents neighbours, based solely on simplifying risk reduction. |
| ClarNEst | = Aggregated expected price for stock s at time t from an agents neighbours, based solely on clarifying risk reduction. |
| Conf | = The agent's confidence level (0 ≤ Conf ≤ 1) |
| Os | = The amount of shares owned in stock s by the agent |
| L | = Loss aversion type |
for t=1 to timespan step agents for each agent update expected values of stocks if there is news Est = Pst-1 + ( Pst-1 * Nst) end end for each agent get expected prices from neighbours NEst = (SimplNEst * Strat) + (ClarNEst * ( 1 - Strat)) Est = ( Est * Conf) + (Nest * (1 - Conf)) end for each agent: place trade orders if Est > Pst then if L = linear B = (cash * (Est — Pst)/Pst * Est) if L = kahneman/tversky B = (cash * ((Est ^ 0.88) — Pst/Pst) * Est) Place buy order for B amount of shares else if Est < Pst then if L = linear S = (Os * |(Est - Pst)/Pst| * Est) if L = kahneman/tversky S = (Os * ( Pst + ( Pst * (-2.25 * (- ( Est - Pst))^0.88))) Place sell order for S amount of shares end end end step market for each stock for each order (in the order placed) if order is buy order match with the lowest priced sell order subtract the amount of shares needed to satisfy the buy order with the amount in the sell order, repeat matching sell orders until the buy order is satisfied the trading price for each transaction is the average of the limits of the two orders if order is sell order match with the highest priced buy order subtract the amount of shares needed to satisfy the sell order with the amount in the buy order, repeat matching sell orders until the sell order is satisfied the trading price for each transaction is the average of the limits of the two orders end Set Pst for each stock to the average trading price end end
|
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2007]