
Keiki Takadama, Tetsuro Kawai and Yuhsuke Koyama (2008)
Micro- and Macro-Level Validation in Agent-Based Simulation: Reproduction of Human-Like Behaviors and Thinking in a Sequential Bargaining Game
Journal of Artificial Societies and Social Simulation
vol. 11, no. 2 9
<https://www.jasss.org/11/2/9.html>
For information about citing this article, click here
Received: 04-Aug-2007 Accepted: 13-Mar-2008 Published: 31-Mar-2008

 Abstract
Abstract
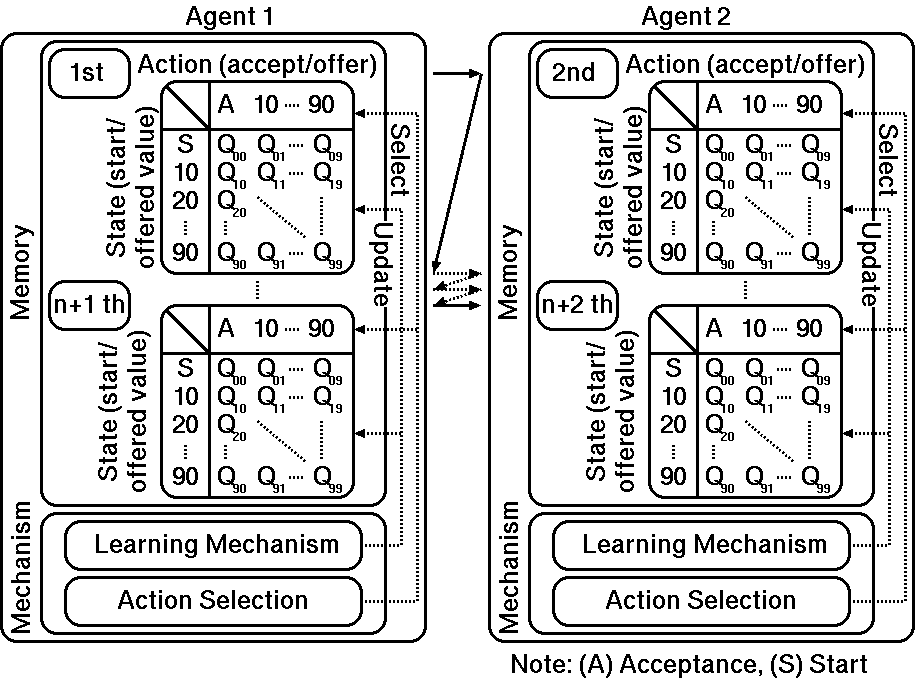
|
| Figure 1. Reinforcement learning agents |
Q(s,a)=Q(s,a)+&alpha[r+&gamma maxa'&isin A(s') Q(s',a')-Q(s,a)]. .... (1)

|
| Table 1. Variables in Q-learning |
P(a|s)=Q(s,a) / &sumai &isin A(s) Q(s,ai ). .... (2)
P(a|s)=eQ(s,a)/T / &sumai &isin A(s) eQ(s,ai )/T. .... (3)
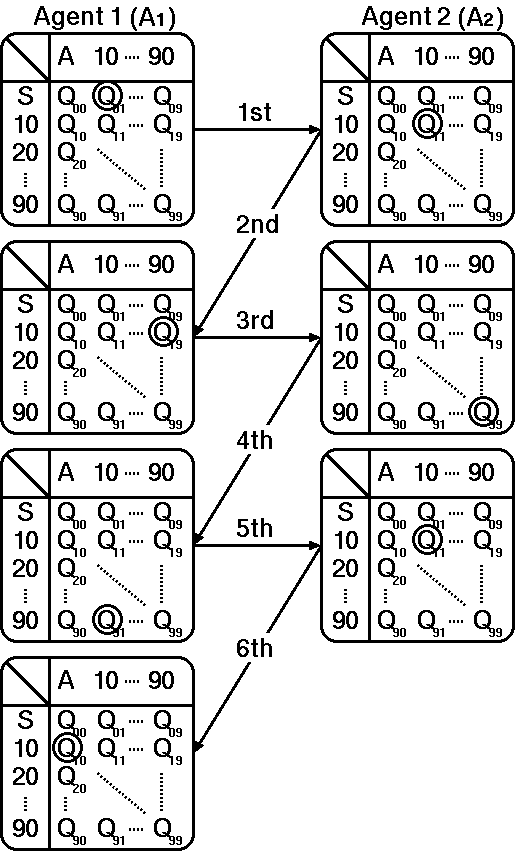
|
| Figure 2. Example of a negotiation process |
&epsilon = &epsilon × (1-ChangeRate) in each interaction, .... (4)
T = T × (1-ChangeRate) in each interaction. .... (5)
Note that (1) the above equations implicitly represent the thinking of human players (i.e., the micro-level behaviors) according to the subject experiment, which is discussed in Sections 5.1 and 5.6; and (2) we do not conduct the simulation of Q-learning agents with the roulette selection mechanism because there is no random parameter in this mechanism.

|
| Table 2. Simulation cases |
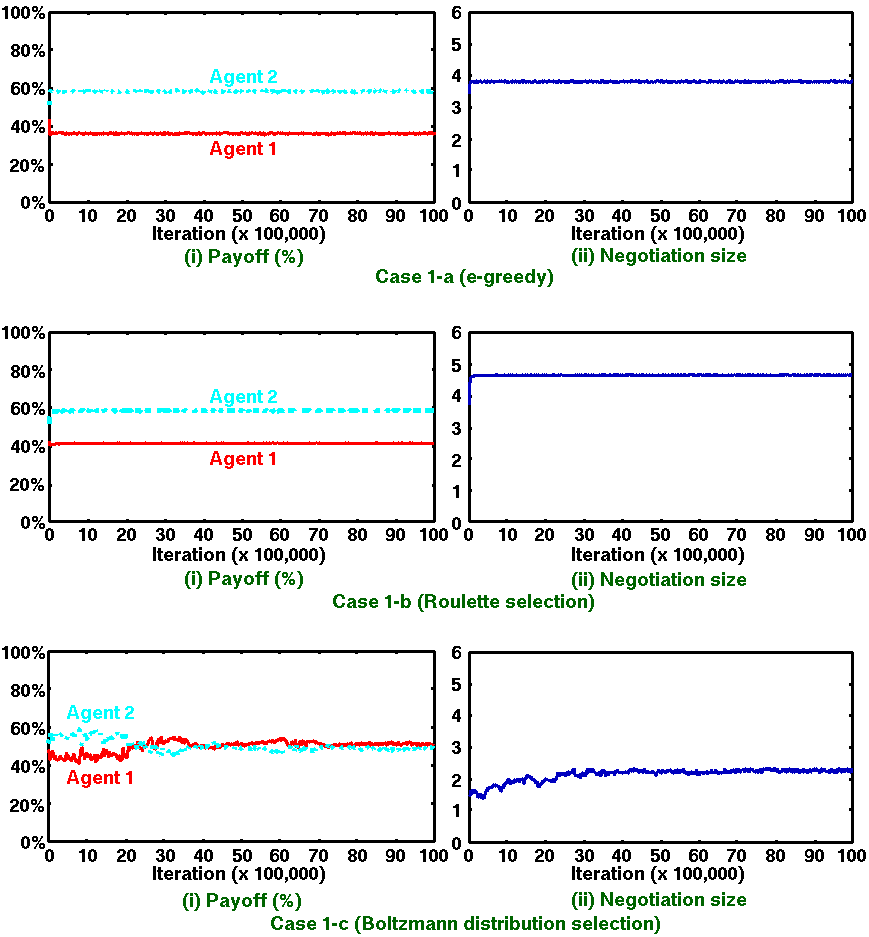
|
|
Figure 3. Simulation results of Q-learning agents (Case 1): Average values over 10 runs through 10,000,000 iterations |
|
|
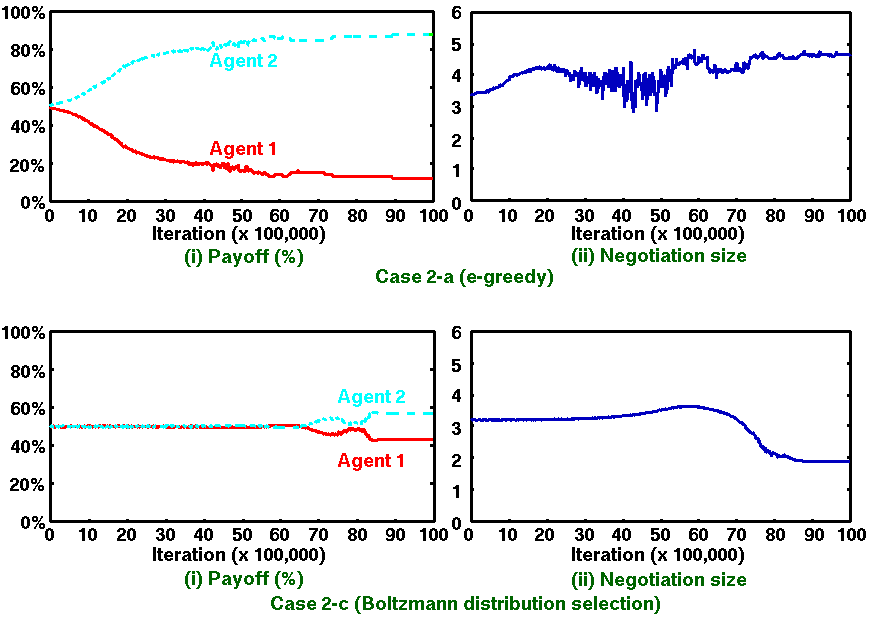
Figure 4. Simulation results of Q-learning agents (Case 2): Average values over 10 runs through 10,000,000 iterations |
|
|
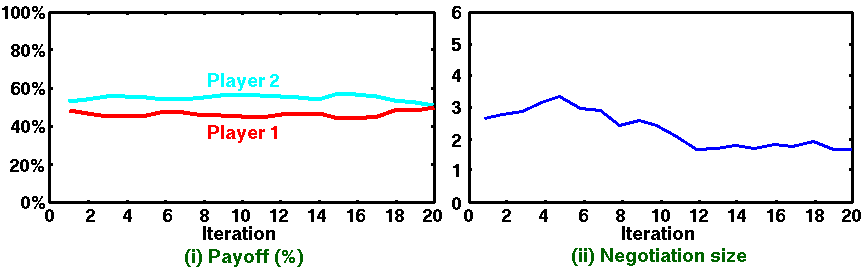
Figure 5. Subject experiment results in
(Kawai 2005): Average values over 10 experiments through 20 iterations |
|
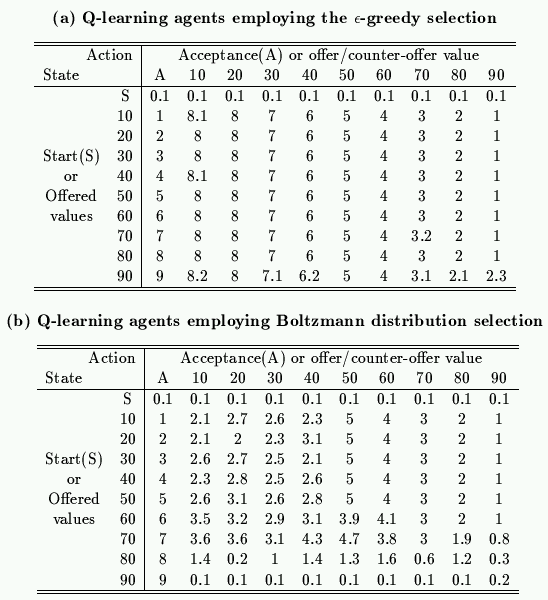
| Table 3. Q-table in Q-learning agents |
Other micro- and macro-level viewpoints can be analyzed instead of the payoffs and the negotiation process size evaluated in our simulations. This indicates that Q-learning agents employing Boltzmann distribution selection with changing the random parameter is only validated from the viewpoints of the payoffs and the negotiation process size. Therefore, further investigations should be done from other micro- and macro-level viewpoints to generalize our results.
Comparing the iterations between the subject experiment and computer simulation, humans require only 20 iterations to learn consistent behaviors and acquire sequential negotiation, while Q-learning agents require 10,000,000 iterations. It seems that Q-learning agents cannot completely reproduce the human-like behaviors from the iteration viewpoint. This is true if agents should be validated in terms of iteration aspect, but the tendency and consistency of the simulation results are important aspects in such comparisons for the following reasons: (1) it is difficult to fairly compare both humans' and agents' results in terms of iteration aspect due to humans by nature having much higher capabilities than Q-learning agents (e.g., Q-learning agents do not have the capability of modeling opponent players). This requires a lot of learning time for agents in comparison with human players; and (2) when we validate agents in terms of the iteration aspect, we should also consider the time of one iteration in the sequential bargaining game. This is because one iteration in a short consideration time is not the same as one in a long consideration time. For example, human players can consider opponents' actions in future steps in a long consideration time. From this viewpoint, human players have the a lot of time to consider in comparison with agents due to the fact that average time of completing 10,000,000 iterations for agents (less than 1 minute) is smaller than that of 20 iterations in human players (10 minutes (Kawai et al. 2005)). It seems that 10,000,000 iterations in agents is not so large for comparing the results in terms of the time aspects. But, as you can easily imagine, it is also not a fair comparison due to the different capabilities of human players and agents.
From the above difficulty of validating agents in terms of iterations, a comparison of humans' and agents' results in terms of the tendency and consistency is important for the first stage of validation. However, an exploration of agents modeling that produces human-like behaviors in short iterations (like 20 iterations) is the challenging issue to overcome the above validation problem.
Focusing on the fairness (or equity) of the payoff, Q-learning agents employing Boltzmann distribution selection derive the roughly equal division of the payoff, which is most similar to the subject experiment result. It should be noted here, however, that (1) the Q-learning mechanism itself does not consider fairness (or equity) of the payoff because it is an optimization method but (2) the integration of the Q-learning mechanism with action selections enables agents to acquire the fairness of behaviors. Especially in the case of introducing the randomness decreasing parameter that reflects human behaviors (i.e., (1) the high randomness of the action selection in the first several iterations corresponds to the stage where players try to explore a larger payoff by competing with each other; while (2) the low randomness of the action selection in the last several iterations corresponds to the stage where players make a mutually agreeable payoff with a small number of negotiations), agents acquires 50% offer for any offers from the opponent agents as shown in Table 3(b). Such results cannot be obtained in the case of other action selection mechanisms. In this sense, Q-learning employing the Boltzmann distribution selections has great potential for providing the fairness of behaviors.
This implication can be supported by other research of the bargaining game in the context of experimental economics (Friedman and Sunder 1994; Kagel and Roth 1995). For example, Nydegger and Owen showed that there is a focal point (Schelling 1960) around the 50% split in the payoff of two players (Nydegger and Owen 1974); Binmore (1988: 209) suggested that fairness norms evolved to serve as an equilibrium selection criterion when members of a group are faced with a new source of surplus and have to divide it among its members without creating an internal conflict; and the results obtained by Roth et al. showed the fairness even though the subjects playing the ultimatum game had distinct characteristic behaviors depending on their countries of origin (precisely, four different countries: Israel, Japan, USA, and Slovenia) (Roth et al. 1991).
The research reported here was supported in part by a Grant-in-Aid for Scientific Research (Young Scientists (B), 19700133) of the Ministry of Education, Culture, Sports, Science and Technology (MEXT), Japan. The authors wish to thank Juliette Rouchier for introducing Gilbert's interesting paper and also thank anonymous reviewers for useful, significant, and constructive comments and suggestions.
AXTELL, R., Axelrod, R., Epstein J., and Cohen, M. D. (1996), "Aligning Simulation Models: A Case Study and Results," Computational and Mathematical Organization Theory (CMOT), Vol. 1, No. 1, pp. 123-141.
BINMORE, K. G. (1998), Game Theory and the Social Contract: Just Playing, Volume 2, The MIT Press.
Bosse, T. and Jonker, C. M. (2005), "Human vs. Computer Behaviour in Multi-Issue Negotiation," First International Workshop on Rational, Robust, and Secure Negotiations in Multi-Agent Systems (RRS'05), IEEE Computer Society Press, pp. 11-24.
CARLEY, K. M. and Gasser, L. (1999), "Computational and Organization Theory," in Weiss, G. (Ed.), Multiagent Systems - Modern Approach to Distributed Artificial Intelligence -, The MIT Press, pp. 299-330.
EREV, I. and Roth, A. E. (1998), "Predicting How People Play Games: Reinforcement Learning in Experimental Games with Unique, Mixed Strategy Equilibria," The American Economic Review, Vol. 88, No. 4, pp. 848-881.
EPSTEIN J. M. and Axtell R. (1996), Growing Artificial Societies, MIT Press.
FRIEDMAN, D. and Sunder, S. (1994), Experimental Methods: A Primer for Economists, Cambridge University Press.
GILBERT, N. (2004), "Open problems in using agent-based models in industrial and labor dynamics," In R. Leombruni and M. Richiardi (Eds.), Industry and Labor Dynamics: the agent-based computational approach, World Scientific, pp. 401-405.
HALES, D., Rouchier J., and Edmonds, B. (2003), "Model-to-Model Analysis," Journal of Artificial Societies and Social Simulation (JASSS), Vol. 6, No. 4, 5 https://www.jasss.org/6/4/5.html.
IWASAKI, A., Ogawa, K., Yokoo, M., and Oda, S. (2005), "Reinforcement Learning on Monopolistic Intermediary Games: Subject Experiments and Simulation," The Fourth International Workshop on Agent-based Approaches in Economic and Social Complex Systems (AESCS'05), pp. 117-128.
KAGEL, J. H. and Roth, A. E. (1995), Handbook of Experimental Economics Princeton University Press.
KAWAI et al. (2005) "Modeling Sequential Bargaining Game Agents Towards Human-like Behaviors: Comparing Experimental and Simulation Results," The First World Congress of the International Federation for Systems Research (IFSR'05), pp. 164-166.
MOSS, S. and Davidsson, P. (2001), Multi-Agent-Based Simulation, Lecture Notes in Artificial Intelligence, Vol. 1979, Springer-Verlag.
MUTHOO, A. (1999), Bargaining Theory with Applications , Cambridge University Press. MUTHOO, A. (2000), "A Non-Technical Introduction to Bargaining Theory," World Economics, pp. 145-166.
NYDEGGER, R. V. and Owen, G. (1974), "Two-Person Bargaining: An Experimental Test of the Nash Axioms," International Journal of Game Theory, Vol. 3, No. 4, pp. 239-249.
OGAWA, K., Iwasaki, A., Oda, S., and Yokoo, M. (2005) "Analysis on the Price-Formation-Process of Monopolistic Broker: Replication of Subject-Experiment by Computer-Experiment," The 2005 JAFEE (Japan Association for Evolutionary Economics) Annual Meeting (in Japanese).
OSBORNE, M. J. and Rubinstein, A. (1994), A Course in Game Theory, MIT Press.
ROTH, A. E., Prasnikar, V., Okuno-Fujiwara, M., and Zamir, S. (1991), "Bargaining and Market Behavior in Jerusalem, Ljubljana, Pittsburgh, and Tokyo: An Experimental Study," American Economic Review, Vol. 81, No. 5, pp. 1068-1094.
ROTH, A. E. and Erev, I. (1995) "Learning in Extensive-Form Games: Experimental Data and Simple Dynamic Models in the Intermediate Term," Games and Economic Behavior, Vol. 8, No. 1, pp. 164-212.
RUBINSTEIN, A. (1982), "Perfect Equilibrium in a Bargaining Model," Econometrica, Vol. 50, No. 1, pp. 97-109.
SCHELLING, T. C. (1960), The Strategy of Conflict, Harvard University Press.
STÅHL, I. (1972), Bargaining Theory, Economics Research Institute at the Stockholm School of Economics.
SPULBER, D. F. (1999), Market Microstructure - Intermediaries and the theory of the firm- , Cambridge University Press.
SUTTON, R. S. and Barto, A. G. (1998), Reinforcement Learning: An Introduction, The MIT Press.
TAKADAMA et al. (2003), "Cross-Element Validation in Multiagent-based Simulation: Switching Learning Mechanisms in Agents," Journal of Artificial Societies and Social Simulation (JASSS), Vol. 6, No. 4, 6. https://www.jasss.org/6/4/6.html
TAKADAMA et al. (2006), "Can Agents Acquire Human-like Behaviors in a Sequential Bargaining Game? - Comparison of Roth's and Q-learning agents -," The Seventh International Workshop on Multi-Agent-Based Simulation (MABS'06), pp. 153-166.
WATKINS, C. J. C. H. and Dayan, P. (1992), "Technical Note: Q-Learning," Machine Learning, Vol. 8, pp. 55-68.
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2008]