
Understanding Artificial Anasazi
Journal of Artificial Societies and Social Simulation
12 (4) 13
<https://www.jasss.org/12/4/13.html>
For information about citing this article, click here
Received: 13-Jun-2009 Accepted: 27-Sep-2009 Published: 31-Oct-2009

 Abstract
Abstract
|
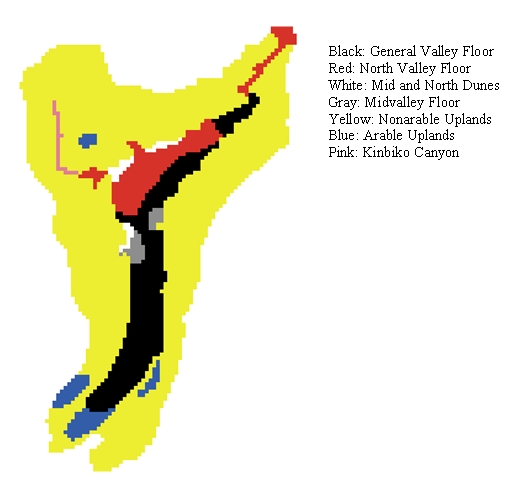
| Figure 1. Different zones of land cover |
| Table 2: Main parameters of the Artificial Anasazi model and their default values | |
| Variable | Value |
| Simulation period | 800 AD to 1350 AD |
| Nutritional need per household | 800 kg per year |
| Number of individuals per household | 5 persons |
| Maximum length of corn storage | 2 years |
| Harvest Adjustment Level | 1.00 |
| Harvest Variance | 0.1 |
| Start of Fertility Age | 16 years |
| End of Fertility Age | 30 years |
| Death Age (maximum age household) | 30 years |
| Fission Probability pf | 0.125 |
| Corn stock given to new household fcs | 0.33 |
| Maximum distance between residence and farm | 1600m |
| BY = y × q × Ha |
where yield y is defined for each zone and each PDSI index (Table 3). For each zone there is a table of yield levels for five levels of PDSI ( (-∞,-3], (-3, -1], (-1, 1), [1, 3), and [3, ∞)). Since the annual PDSI indicates whether the year was a wet year, high PDSI, or a dry year, low PDSI, the annual yield can change from year to year. The default value of Ha is 1 and is used for calibration.
| Table 3: The yield levels for the different values of PDSI | ||||
| Zones | ||||
| PDSI | North and Mid Valley, Kinbiko Canyon | General Valley | Arable Uplands | Dunes |
| (-∞,-3] | 617 | 514 | 411 | 642 |
| (-3,-1] | 719 | 599 | 479 | 749 |
| (-1,1) | 821 | 684 | 547 | 855 |
| [1,3) | 988 | 824 | 659 | 1030 |
| [3,∞) | 1153 | 961 | 769 | 1201 |
| H0 = BY × (1 + n(0,σahv)) |
|
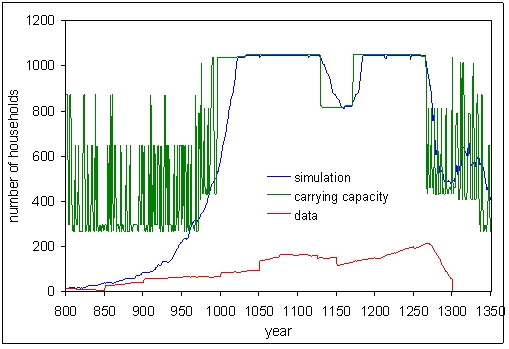
| Figure 2. Results using the default parameter values. The blue line simulation is the number of households simulated by the model version as used in Dean et al. (2000). The red line data is the estimated number of households based on archaeological data. The green line carrying capacity is the amount of households possible on the landscape based on the number of cells that produces enough food for one household. |
|
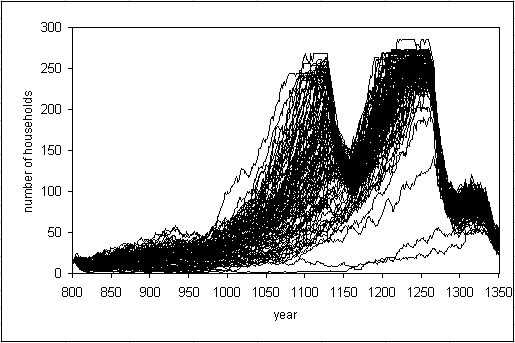
| Figure 3. 100 runs with the "calibrated" Artificial Anasazi |
|
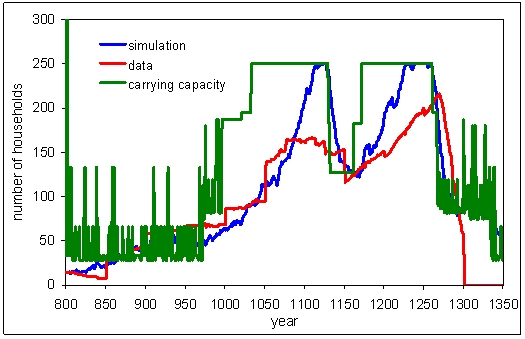
| Figure 4. Simulated ("best" fit) and historical data and the carrying capacity for the parameter values from Axtell et al. (2002) |
| Table 4: Optimized parameter settings based on the average over 15 runs of the model for the replicated model, the carrying capacity model and the original model. The values between brackets in the last 2 columns refer to the lower and upper range of the uniform distribution of the parameter values. | ||||
| L1 and L2 population and L2 carrying capacity | L1 carrying capacity | L1 population (Axtell et al. 2002) | L2 population (Axtell et al. 2002) | |
| Death age | 38 | (30-36) | (25-38) | |
| End of Fertility Age | 34 | (30-32) | (30-38) | |
| Fission Probability | 0.155 | 0.125 | 0.125 | |
| Harvest Adjustment | 0.56 | 0.54 | 0.6 | 0.6 |
| Harvest Variance | 0.4 | 0.4 | 0.4 | 0.4 |
|
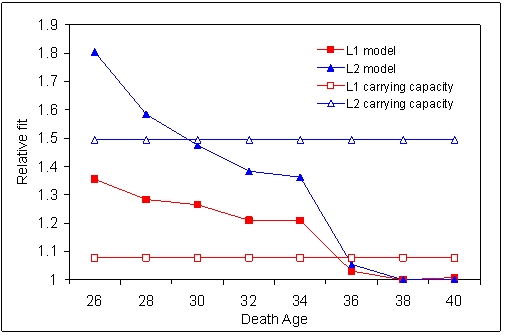
| Figure 5. Relative fit of the replicated Artificial Anasazi model as a function of the parameter Death Age. The values are the best average over 15 runs for all simulations with that particular value of Death Age. |
|
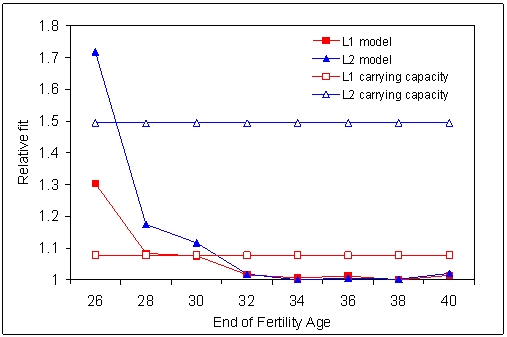
| Figure 6. Relative fit of the replicated Artificial Anasazi model as a function of the parameter End of Fertility Age. The values are the best average over 15 runs for all simulations with that particular value of End of Fertility Age. |
|
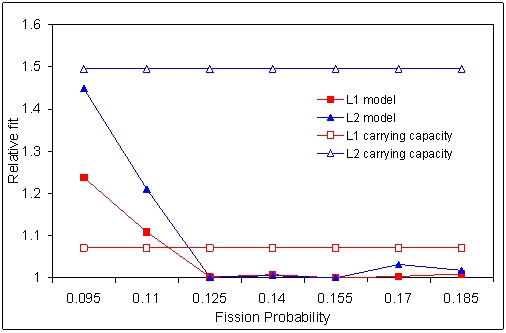
| Figure 7. Relative fit of the replicated Artificial Anasazi model as a function of the parameter Fission Probability. The values are the best average over 15 runs for all simulations with that particular value of Fission Probability. |
|
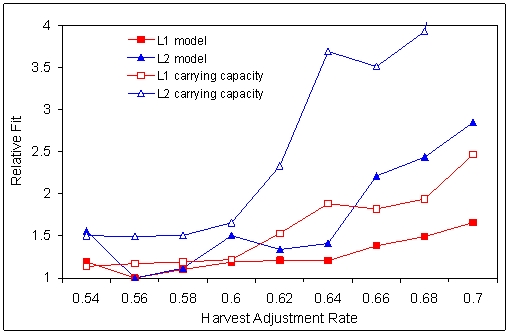
| Figure 8. Relative fit of the replicated Artificial Anasazi model as a function of the parameter Harvest Adjustment Level. The values are the best average over 15 runs for all simulations with that particular value of Harvest Adjustment Level. |
|
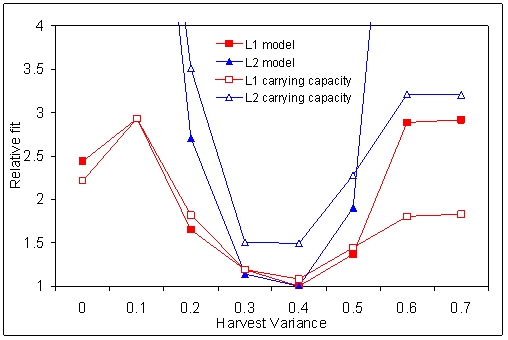
| Figure 9. Relative fit of the replicated Artificial Anasazi model as a function of the parameter Harvest Variance. The values are the best average over 15 runs for all simulations with that particular value of Harvest Variance. |
|
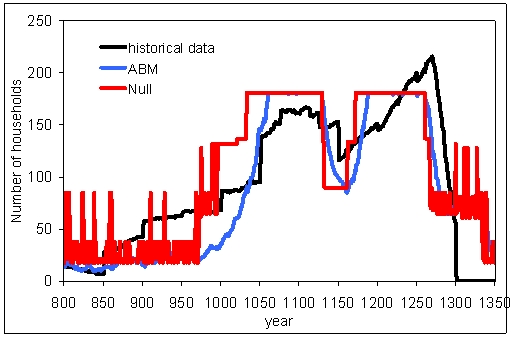
| Figure 10. Best individual run for the agent-based model and the population numbers according to the carrying capacity model using the L2 metric and the parameter values from the second column. |
"Each household that is both matrilineal and matrilocal consists of 5 individuals. Only female marriage and residence location are tracked, although males are included in maize-consumption calculations. (Table 1, page 7276)"
"A household fissions when a daughter reaches the age of 15. (Table 2, page 7277)"The code uses an annual time step while the paper suggests that there are monthly time steps:
"A second clock runs from April to April and reduces the amount of maize in storage by 13.33 kg of maize per month per individual in the household. (Table 3, page 7277)"We follow the code instead of the description in performing our analysis.
DEAN J S, Gumerman G J, Epstein J M, Axtell R L, Swedlund A C, Parker M T, and McCarroll S. (2000) Understanding Anasazi Culture Change Through Agent Based Modeling in Dynamics in Human and Primate Societies: Agent Based Modeling of Social and Spatial Processes, T. Kohler and G. Gumerman (eds.), Santa Fe Institute. New York & London: Oxford University Press.
DIAMOND, J. (2002) Archaeology: Life with the artificial Anasazi, Nature 419: 567-569.
EDMONDS, B and HALES, D (2003) Replication, Replication and Replication: Some Hard Lessons from Model Alignment, Journal of Artificial Societies and Social Simulation 6 (4) 11 https://www.jasss.org/6/4/11.html.
GRIMM V, Berger U, Bastiansen F, Eliassen S, Ginot V, Giske J, Goss-Custard J, Grand T, Heinz S, Huse G, Huth A, Jepsen J U, Jørgensen C, Mooij W M, Müller B, Pe'er G, Piou C, Railsback S F, Robbins A M, Robbins M M, Rossmanith E, Rüger N, Strand E, Souissi S, Stillman R A, Vabø R, Visser U, DeAngelis D L. (2006) A standard protocol for describing individual-based and agent-based models. Ecological Modelling 198:115-126.
GUMERMAN G J, Swedlund A C, Dean J S, and Epstein J M (2003) The Evolution of Social Behavior in the Prehistoric American Southwest. Artificial Life 9: 435-444
JANSSEN, M A Population aggregation in the ancient arid environments, in review
KOHLER, T A , Gumerman, G J and Reynolds, R G (2005) Simulating ancient societies, Scientific American 293(1): 76-82
KOHLER, T A and van der Leeuw, S A (eds) (2007) The Model-based Archaeology of Socionatural Systems, School for Advanced Research Press.
KOHLER, T A, Varien M D, Wright A and Kuckelman K A (2008) Mesa Verde Migrations: New archaeological research and computer simulation suggest why ancestral Puebloans deserted the northern Southwest United States. American Scientist 96:146-153
MACY M and Sato Y (2002) Trust, cooperation and market formation in the US and Japan. Proceedings of the National Academy of Sciences, 99, pp. 7214-7220.
REYNOLDS, R G, Kohler, T A and Kobti, A (2003) The Effects of Generalized Reciprocal Exchange on the Resilience of Social Networks: An Example from the Prehispanic Mesa Verde Region, Computational & Mathematical Organization Theory, 9, 227-254
RIOLO, R L, Cohen, M D and Axelrod, R (2001), Evolution of cooperation without reciprocity. Nature, 411:441-443.
WILL, O, and Hegselmann, R (2008). 'A Replication That Failed - on the Computational Model in 'Michael W. Macy and Yoshimichi Sato: Trust, Cooperation and Market Formation in the U.S. and Japan. Proceedings of the National Academy of Sciences, May 2002''. Journal of Artificial Societies and Social Simulation 11 (3) 3 https://www.jasss.org/11/3/3.html
 Return to Contents of this issue
Return to Contents of this issue
© Copyright Journal of Artificial Societies and Social Simulation, [2009]