
Introduction
Computer simulation has been recognised and is increasingly used by geographers as an efficient tool to explore geographical processes, hypotheses and predictive scenarios within virtual laboratories (Batty 1971, 2007b; Carley 1999; Quesnel et al. 2009). It has been identified as an emerging field and coined under the term geosimulation by Benenson & Torrens (2004). Simulation also appears as a way to overcome the difficult analytic resolution of many socio-spatial models which were developed in the past, as well as to explore the possible (alternative) trajectories of path-dependent social and ecological systems. The specificity of geographical models compared to other social science models is that space and spatial interactions are given a prime role, geographers being driven by an explicit interest in studying the way "space" in a broad sense, and more specifically geometry or topology of space influences the outcomes of social processes modelled. We think that simulation approaches are uniquely positioned to represent the complexity of socio-spatial interactions, provided that models include relevant spatial descriptions and behavioural rules which take spatial proximity into account, and provided that the model evaluation includes a sensitivity analysis of the model outputs to the way space is represented. Unfortunately, the first condition is not always met, and the second is seldom even mentioned. Various contributions have been made on ad hoc models to test for the influence of geometry on simulation outputs (Lilburne & Tarantola 2009; Sun & Wang 2007), but without providing a generic framework fitted for most agent-based models. This paper aims to fill a methodological and conceptual gap, which is a systematic testing of the sensitivity of a model’s outcomes to its initial spatial conditions. To demonstrate the genericity of our approach, we develop two applications with classic simulation models commonly used as case studies for comparing and aligning simulation models (Axtell et al. 1996; Wilensky & Rand 2007): Schelling (1971)’s model of segregation and Epstein & Axtell (1996)’s Sugarscape model of unequal societies.
Definition of the problem
Socio-spatial systems can be crudely described as social agents interacting with one another via the geometric structure of space. Social agents thus constitute the microscopic level of the system, and they are contained within a spatio-temporal structure that evolves with potential cumulative effects, also known as path-dependency (Arthur 1994). Therefore, observing one system at different points in time does not equate to observing different systems at a single point in time. This general property of non-ergodicity applies to geographical elements such as road networks or built-up areas (Pumain 2003). Similarly to what Gell-Mann (1995) calls frozen accidents in complex systems generally, a given configuration contains clues about past bifurcations, that can have had dramatic effects on the state of the system. Therefore, strong spatio-temporal path-dependencies in the trajectory of individual territories and changing social environments over time prohibit the use of ergodic models. Ironically, these very models tend to be the models most frequently used in geosimulation. With this kind of models, the influence of the geometric structure of space will be even more important than in the case without path-dependency.
Self-organization has been shown to be a central feature of socio-spatial systems in general and of cities in particular (Allen & Sanglier 1981; Saint-Julien et al. 1989; Portugali 2000). In the vocabulary of complex systems, cities also exhibit emergent properties at macroscopic scales (Pumain 2006; Aziz-Alaoui & Bertelle 2009), which can be simulated through microscopic interactions between agents (Wu 2002; Batty 2007a). Complexity is partially due to bifurcations, which are determinant in socio-spatial systems (Wilson 1981, 2002). Indeed, in spatially explicit simulation models, the non-linearity of local interactions is very likely to sublimate small perturbations in the initial spatial setting, making it difficult to interpret the resulting global structures. In that sense, the impact of initial spatial settings on final outcomes is assumed to be significant just as any other initial conditions, but of more interest to the geographer.
Finally, although this may seem obvious, cities are not regular grids, and the distribution of density (of jobs, residents, buildings, etc.) is far from isotropic, even in sprawled cities. On the contrary, there is a significant diversity in the way people, activities and structures are distributed within cities. In Europe for example, Le Néchet (2015) quantifies and classifies six broad types of residential density distributions. However, most socio-spatial models, especially cellular automata, still represent cities, hence geometric support of spatial interactions, as uniform grids of isotropic density. Even in applied cases when GIS geometries of a particular city are used, the spatial distribution of agents tend to be approximated by a constant density (Arribas-Bel et al. 2016), although previous research shows that it is computationally and methodologically feasible to use accurate locations in a simple model such as Schelling’s (Benenson et al. 2002). The isotropic simplification is potentially harmful to the representation of urban processes because density and accessibility have environmental, economic and social consequences. Additionally, we expect the initial spatial distribution of agents to influence simulation results in the long run (Castellano et al. 2009), because the agents’ rule of action itself may depend on the spatial structure of the environment. For example, households can have different preferences with respect to the built-environment they might want to live in (Spielman & Harrison 2014), or agents moving around will sense a different set of objects within the same fixed radius depending on the topology (Banos 2012) and distribution of density of the sensed environment (Laurie & Jaggi 2003; Fossett & Dietrich 2009). The way modellers represent the initial geometry of space is therefore a central element of socio-spatial simulation models. However, this step is rarely explicit. A meaningful way to address it might be to consider, not necessarily the peculiarities of every city, but at least their broad density structures so as to estimate the variability of the model behaviour to different plausible spatial arrangements.
Objective
In this article, we aim to provide an operational framework for studying the influence of geometric structures of space on the results of a simulation model representing a sociospatial system. Following Jessop et al. (2008) socio-spatial systems are understood here as groups of social agents whose behaviour is constrained by their position in geographical space. The aim of the geosimulation models we are interested in is to represent, simulate and explain the dynamics of these systems. In the sociospatial systems as well as in the models representing them, agents are in interaction with other agents and with their geographical environment. The geometric structure of the environment defined at the initialisation of the model and its influence on the model outputs are our object in this paper. We present how to generate the geometric outputs which are used as initial spatial conditions in the model. To this end, we use the example of a density grid generator and feed its outputs to two application models (Schelling and Sugarscape). In no way do we pretend to provide a full exploration of these two particular models, of their attractors and/or potential policy implications. Instead, we present a way of performing a sensitivity analysis to initial spatial conditions of models generated systematically. The generator being controlled by its own parameters, we can then relate the parameters used to generate initial spatial conditions to the variation of simulation outcomes. The purpose is two-fold: (i) to test the robustness of simulation results to small variations of generator parameters and (ii) to study the non-trivial effects of typical categories of geometric structures (monocentric vs. polycentric for example) on the results of a given model. Our approach allows for a systematic comparison of several aspects of the spatial configuration problem, which have been suggested by Filatova et al. (2013), but to the best of our knowledge hardly implemented and achieved in previous studies. In particular, it is applied to the effects of urban form on simulation results, using Schelling’s model as a first case study and Sugarscape model as a second one.
The Effects of Space in Simulation Models
Spatial processes
Several empirical studies emphasize the statistical correlations between spatial configurations of people in a city and different distributions of income, carbon emissions, educational outcomes, etc. For example, Wheeler (2006) shows that, in the US, sprawling cities are more unequal than their compact counterparts with respect to income. Dynamically, sprawl in American cities consists in the addition of new developments which have been occupied by different groups of population, resulting in a concentration of the wealthy in suburban pockets and of pockets of poverty in the inner city area (Jargowsky 2002). Similarly, in terms of pollution for example, Schwanen et al. (2001, p.173) show that “deconcentration of urban land uses encourages driving and discourages the use of public transport as well as cycling and walking”. These effects of geographical space on social systems correspond to processes to be included in geosimulation models, as a way to disentangle sources of variation arising from socio-spatial processes and from the initial configuration of the geometry of space.
Spatial representation
A discussion of the effects of spatial encoding and representation has also been associated with the field of geostatistics since the exposure of the Modifiable Areal Unit Problem (MAUP) (Openshaw 1984; Fotheringham & Wong 1991). For example, Kwan (2012) has argued for a careful examination of what she coins the ’uncertain geographic context problem’ (UGCoP), i.e. of the spatial configuration of geographical units even when the size and delineation of the area are the same. Considerations of such issues in the geosimulation literature are rather scarce. However, there have been some noticeable attempts at analysing the impact of three types of initial spatial characteristics on model outcomes:
- The accuracy of geo-localised input data. Thomas et al. (2017) show that data selection in LUTI model is inter-related with the delineation of the spatial system boundaries and the scale of analysis. They provide a few examples on how the use of Exploratory Spatial Data Analysis (ESDA) prior to simulation runs can help avoiding measurement errors of model behaviour and outcomes. In the context of spatial interaction models, Hagen-Zanker & Jin (2012) acknowledge the dilemma between spatial resolution and the computational burden, and suggest a method of adaptive zoning (where the size of destination zones depends on the distance to origin) to solve it.
- The shape, precision and boundaries of the modelled spatial system. Axtell et al. (1996) highlight the sensitivity of the average number of stable cultural regions generated to the effect of the territory width implemented in a version of the Sugarscape model which is docked (i.e. made equivalent to) to Axelrod Culture Model. Flache & Hegselmann (2001) show that chances for random emergence of a stable cluster of similar agents in a Schelling-like model are higher in a rectangular grid and lower in a hexagonal grid and that an irregular (Voronoi-diagram) city lattice structure favours migration stabilisation around decentralised clusters of similar agents. Banos (2012) compares the behaviour of Schelling segregation model on city lattices formalized as either grid, random, scale-free and Sierpinski networks and concludes that the presence of cliques in graph-based urban structures favours segregationist behaviours. Le Texier & Caruso (2017), using a set of different theoretical spatial systems, demonstrate the impact of the regularity and aggregation levels, or centrality/periphery effects, on spatial diffusion dynamics of euro coins. Similar issues were also dealt with in physical sciences: for example, Horritt & Bates (2001) study the effects of grid cell size on the behaviour of a raster flood model and show that increasing resolution does not increase model prediction performance below a certain level. Similar conclusions are obtained by Vázquez et al. (2002), unveiling an intermediate optimal spatial resolution regarding model performance and computation time. Spatial resolution also plays a role in the Schelling model: Singh et al. (2009) show that the segregation patterns for certain tolerance values are strictly a small city phenomenon (8x8 city- lattice) and do not work for a larger spatial lattice (100x100), where segregation appears only for certain combinations of tolerance threshold and vacancy density values.
- The degree of spatial heterogeneity modelled. Stauffer & Solomon (2007) introduce asymmetric interactions and empty residences in Schelling’s model run on a large and regular lattice. They reveal conjoint and non-linear effects on the vacancy rates and tolerance levels on segregation patterns. Gauvin et al. (2010) run Schelling’s segregation process in an open city-lattice to study how the variations in tolerance levels, vacancy rates and city attractiveness may create lines of vacancy lots between clusters of agents. They conclude on the functional role of vacancies, which allow weakly tolerant agents to live and be satisfied in a city environment they nevertheless perceive as hostile. Hatna & Benenson (2012) show that their model replications run on a 50x50 torus with 2% of empty cells were not sensitive to the initial patterns (random and fully segregated distribution of agents). In ecology, Smith et al. (2002) study the spread of a disturbance in a heterogeneous landscape using a percolation model, and show that landscape structure has a significant influence on final patterns of contamination outcome. In a spatial epidemics model for an infectious disease, parameterised on real data, Smith et al. (2002) finds that the physical landscape heterogeneity, in particular the presence of rivers, locally influence the propagation speed.
Spatial structures
We can distinguish a last category of spatial effects in geosimulation, which are the geometric constraints of the environment modelled at initialisation on the course and output of the simulation. Our original contribution is to tackle this type of spatial effects. In this paper, we present an operational framework which allows us to systematically measure the impact of the initial geometric structures on the aggregate behaviour of simulation models. We illustrate the potential genericity of our approach by applying it to two distinctive agent-based models: Schelling's model and Sugarscape.
Methods
The general workflow of our method is illustrated in Figure 1. In addition to the usual protocol (upper branch of the figure), which consists of running a model \(\mu\) with different values of its parameters, we introduce a density grid generator which depends on its very own set of parameters and feeds the model \(\mu\) at initialisation (lower branch). We call these parameters \(\gamma\) parameters to distinguish them from the standard parameters of the models (called \(\mu\) parameters). The resulting configurations can be clustered into qualitative types of spatial patterns. The sensitivity analysis relates the variations in the model’s outcomes to how the density spatial distribution was generated and to the patterns of density generated. In particular, we want to emphasize that spatial effects derive not only from grid size or shape effects, but also from the heterogeneity of the spatial distribution of socio-spatial entities (people, housing, networks, etc.). In the models we used as examples, the initial spatial configurations can be either flat or heterogeneous, monocentric or polycentric, based on external databases and on internal modelling - generation of synthetic population for instance (Bhat & Koppelman 1999).
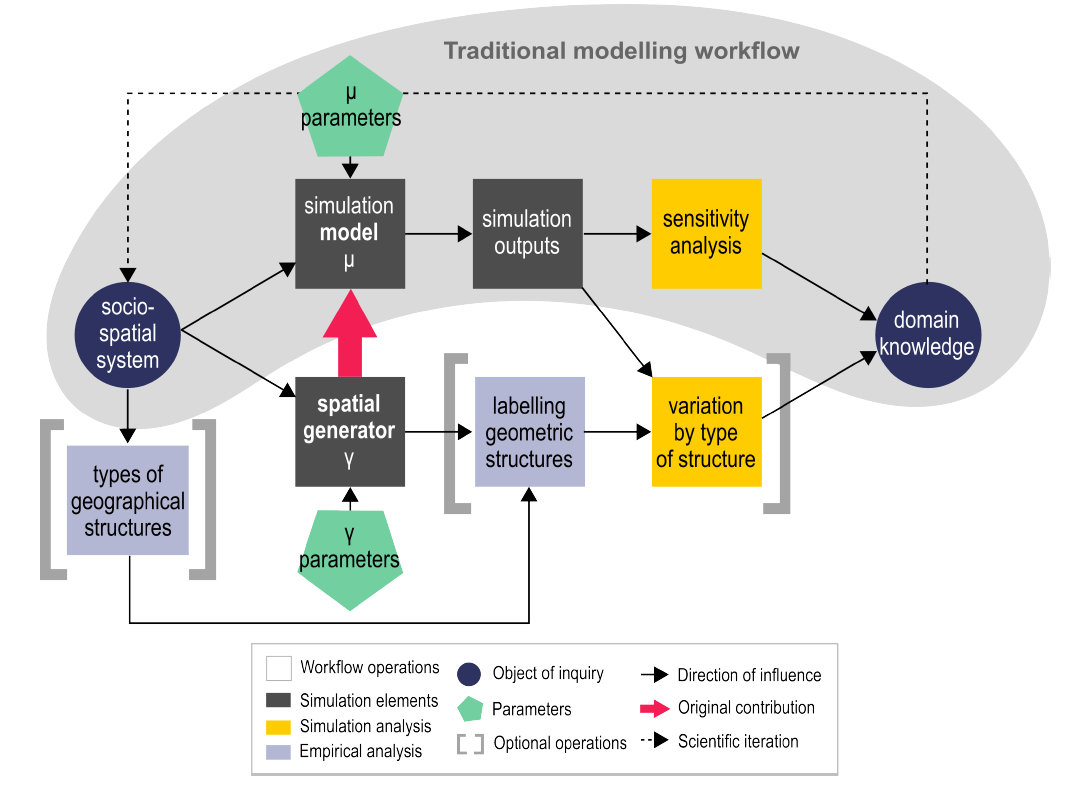
In order to test the influence of initial spatial conditions on model outputs, we use a systematic method to compare phase diagrams. Following Gauvin et al. (2009), we define a phase diagram as the vector of final aggregated model outputs considered as a function of model parameters. We have as many phase diagrams as we have spatial grids, which makes a qualitative visual comparison not realistic (with around 50 different spatial configurations for each model experiment). A solution is to use systematic quantitative procedures to compare them to a reference case. Technically, because of stochasticity, we represent the output of the model for a given set of parameter values as the mean of the final values of an output indicator obtained for the replications of the model initialized with the set of parameter values. To our knowledge there exists no single well-established method to compare phase diagrams in the agent-based modelling and geosimulation literature (see discussion below). We introduce a measure of the relative distance \(d_r(\mu_{\vec{\gamma}_1},\mu_{\vec{\gamma}_2})\) between two phase diagrams \(\mu_{\vec{\gamma}_1}\) and \(\mu_{\vec{\gamma}_2}\). Phase diagrams are denoted by the same function \(\mu\) indexed by the generator parameters \(\vec{\gamma}\), which capture the spatial configuration (in practice these can be parameters of an upstream model to generate the configuration, or a description of the configuration itself). We choose to compare the inner variability of each phase diagram to the variability between them. We take therefore a simple a-dimensional ratio measure, given formally in the case of a one-dimensional phase diagram by
| $$d_r\left(\mu_{\vec{\gamma}_1},\mu_{\vec{\gamma}_2}\right) = 2 \cdot \frac{d(\mu_{\vec{\gamma}_1},\mu_{\vec{\gamma}_2})^2}{Var\left[\mu_{\vec{\gamma}_1}\right] + Var\left[\mu_{\vec{\gamma}_2}\right]}$$ | (1) |
The last methodological point which we need to emphasize is the relationship between the present workflow and model exploration workflows in general. The ideas of multi-modelling and extensive model exploration are nothing from new - Openshaw (1983) already advocated for “model-crunching” in 1983 -, but their effective use only begins to emerge thanks to the development of new methods and tools together with an explosion of computation capabilities. The model exploration platform OpenMOLE (Reuillon et al. 2013) allows to embed any model as a blackbox, to write flexible exploration workflows using advanced methodologies such as genetic algorithms and to distribute transparently the computations on large scale infrastructures such as clusters or computation grids. While tools and platforms providing similar functionalities exist, such as for example Behavior Space of NetLogo (Tisue & Wilensky 2004) for model exploration, Bakker et al. (2016) for interactive model development, or interfaces to access High Performance Computing services (Vecchiola et al. 2009), none provide the three aspects simultaneously in an integrated manner. In our case, this tool is a powerful way to embed both the sensitivity analysis and the sensitivity analysis to initial spatial conditions, and to allow the coupling of any spatial generator with any model in a straightforward way as long as the model can take its spatial configuration as an input or from an input file. In this paper, we use the OpenMOLE platform for the spatial environment and the model coupling, placing ourselves in the framework of multi-modelling (Cottineau et al. 2015). We use therefore OpenMOLE’s functionalities for model embedding through workflow, design of experiments (parameter sampling) and high performance environment access. As our method quickly increases the amount of computation needed (we ran models approximatively \(7\cdot 10^6\) times with a total computation time of around 2 years equivalent CPU), the use of OpenMOLE was crucial in our work.
Spatial generator of density grids
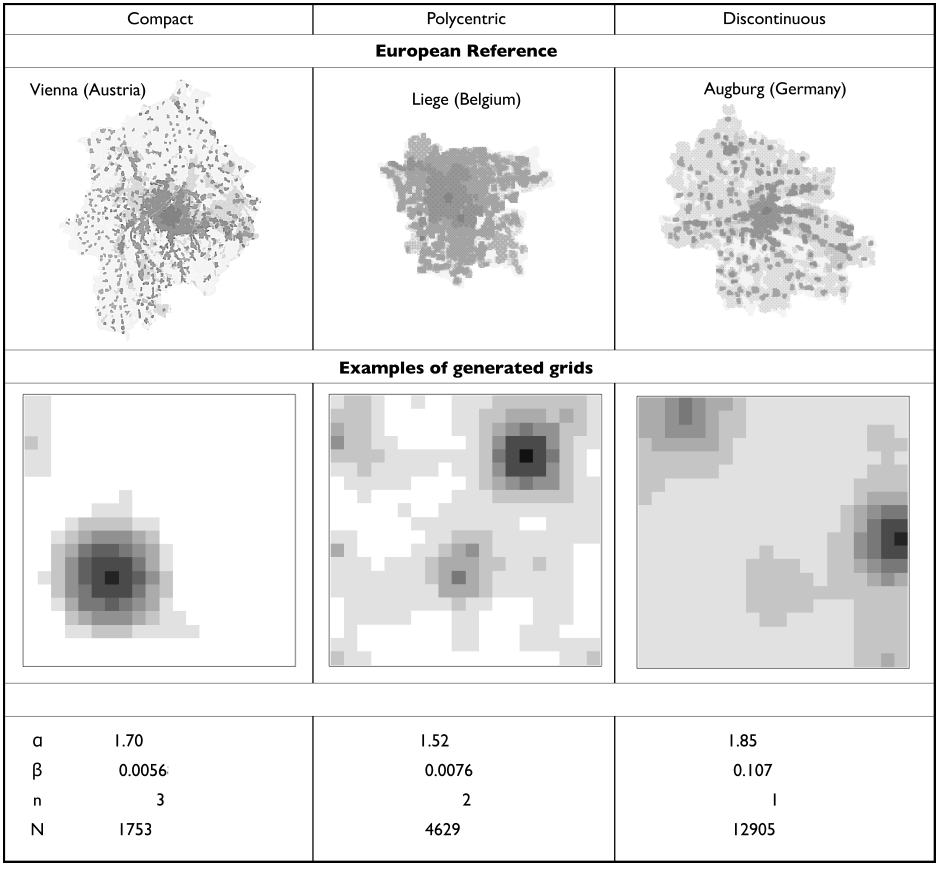
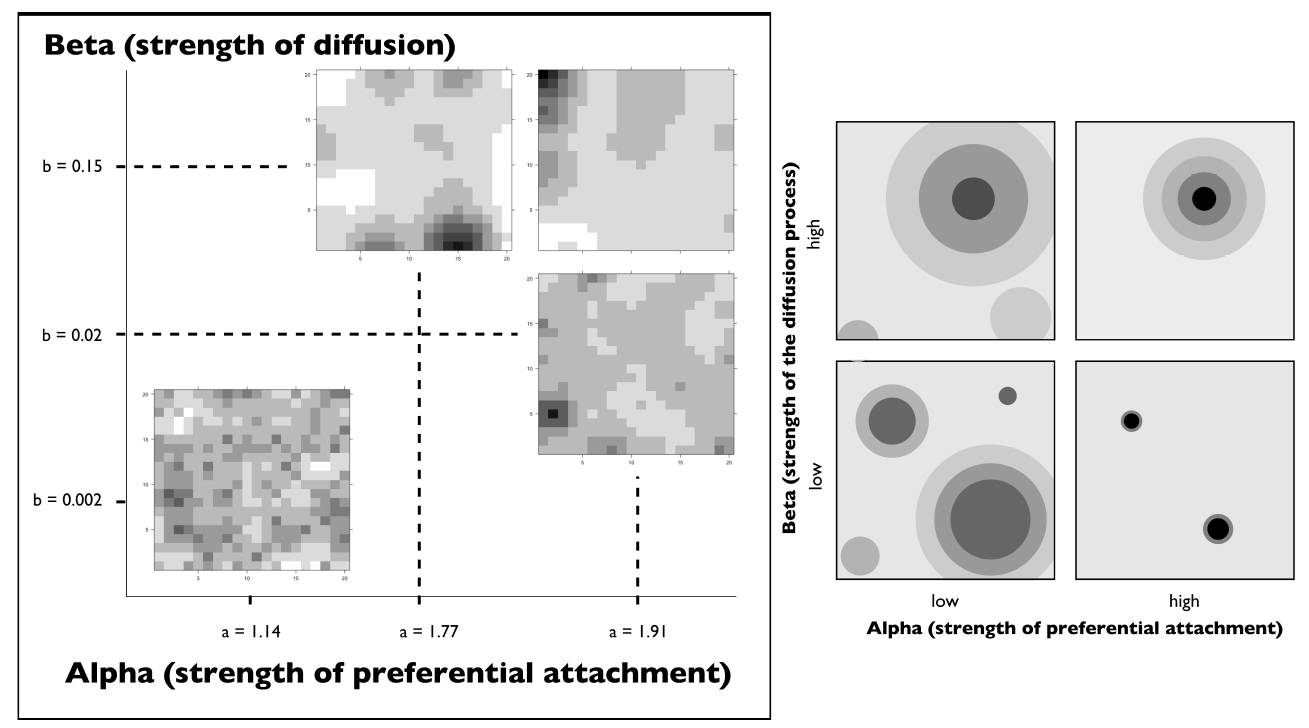
The density grid generator applies an urban morphogenesis model (Batty 2007a) which has been generalised, explored and calibrated by Raimbault (2018a). To generate population density distributions, other models such as other morphogenesis models (Rybski et al. 2013), kernel mixtures (Anas et al. 1998) or more operational cellular automaton models of urban growth (Herold et al. 2003) could be used, as our general method is proposed to be independent of the generators and models chosen. The model of Raimbault (2018a) has the advantage of producing a broad range of existing urban forms with a reasonable level of complexity. An open implementation and a characterisation of the urban forms which the model can produce allow us to integrate it easily into our workflow. Population density grids, at the typical scale of a metropolitan area, are generated by combining the opposite processes of urban dispersal (negative externalities) with urban concentration (positive externalities). More precisely, grids are generated through an iterative process which simulates successive time steps with a fixed population gain at each time step. Starting from an empty grid, the model adds a quantity \(N\) (population) at each time step \(t\). The new population is allocated through preferential attachment on previous population density. Formally, each added unit has a probability equal to \(P_i^{\alpha}/\sum_k P_k^{\alpha}\) to be added to a patch \(i\) with population \(P_i\), all \(N\) units being added independently and in parallel. The attachment parameter \(\alpha\) can thus be interpreted as a "strength of attraction", in the sense that increasing it will lead to a higher instantaneous concentration. At the end of each time step, this growth process is smoothed \(n_d\) times using a diffusion process: each patch transmits an equal share of \(\beta\cdot P_i\) to its Moore neighborhood (i.e. its 8 surrounding patches). The parameter \(\beta\) can be interpreted as a strength of diffusion: increasing it will lead to larger share of population being diffused in space. To avoid border effects such as a reflexion on the border of the world, border patches diffuse to the outside. The procedure stops when a fixed number of steps \(t_f\) is reached. The grid then has a population of \(t_f \cdot N\) (the population lost due to diffusion process to the outside is reallocated through a normalization procedure at the end of the steps). Grids are thus generated from the combination of the values of these four generator parameters \(\alpha\), \(\beta\), \(n_d\) and \(N\), in addition to the random seed. To ease our exploration, only the distribution of density is allowed to vary rather than the size of the grid, which we fix to a 50x50 square environment (this size provides a good compromise between accuracy of the model to reproduce forms and computational complexity, and furthermore corresponds to the order of magnitude of raster grids for metropolitan areas). We furthermore fix the total population at \(t_f\cdot N = 100,000\), and determine therein the number of steps needed at a given \(N\). Typical value ranges for the parameters will be taken as, following Raimbault (2018a), \(\alpha\in\left[0.5,4.0\right]\), \(\beta \in\left[0,0.3\right] \), \(N\in \left[100,10000\right]\), \(n_d\in\left[1,4\right]\). We illustrate in Figure 2 the variety of spatial configurations that can be generated.

In order to generate density grids which correspond to empirical density distributions, we select among the generated grids using an objective function which matches the point cloud of 110 metropolitan areas in Europe described by four dimensions of spatial structure: their concentration index, hierarchy index, centrality index and homogeneity index (cf. Le Néchet (2015)). These four dimensions were chosen as complementary descriptors of spatial organisation at the urban or metropolitain level - see also Tsai (2005) and Schwarz (2010). They account for: (i) the extent to which population is clustered in a central city, with two complementary indicators : the Moran spatial autocorrelation index (called "centrality") and the distance between individuals ("concentration"), (ii) the extent to which density grid values are similar or contrasted, regardless of location, with two complementary indicators: the entropy of the cell density distribution ("homogeneity") and its rank-size slope ("hierarchy").
We sample the \(\gamma\) parameter space using a Latin Hypercube Sampling(LHS), which is a convenient technique to lower the scatter discrepancy in high dimensions. We sample 2000 points in the 4-dimensional space of parameters {\(\alpha\), \(\beta\), \(n_d\), \(N\)}. It yields a subset of 170 grids matching empirical densities, which constituted our set of different initial spatial conditions. These are further clustered into three classes of morphology (Figure 3) that we label ’compact’ (e.g. Vienna), ’polycentric’ (Liege) and ’discontinuous’ (Augsburg) after Le Néchet (2015). This clustering allows to evaluate the non-trivial effects of a meaningful urban form on simulation results. We select 15 grids of each type to capture possible variations within and between different types of grid. The spatial generator and its resulting grids are relevant to the case study models we have picked (Schelling and Sugarscape) because it produces density grids at a “metropolitan scale”, which is the scale at which both models were initially intended to be. In the case of Schelling’s segregation model for example, this scale is the one at which most empirical segregation indexes are computed and compared to the model outputs. In the case of Sugarscape, it corresponds to the whole city if the model is a metaphor for city resources (Batty 2005), or to a generic landscape where a resource is grown otherwise. In both cases, our point is that there exist many different patterns of density distribution in resource location and urban density and that acknowledging this diversity might lead to variations in the model outputs. Furthermore, in urban models, we argue that the hypothesis of isotropic density is potentially the most unrealistic one, although unfortunately the most common one in Schelling implementations.
In the following section, we briefly recall the main components of the two “classical” agent-based simulation models used to test how spatial density variations may impact the behaviour and results of simulation models, and how general the method is.
Case study models
Schelling
Schelling’s model consists in an abstract urban housing market where agents of different attributes (for example: red or green) sense their environment, evaluate their satisfaction in terms of neighbourhood composition (how many reds and greens?), and relocate if unsatisfied. It has been shown by Schelling (1969) that even tolerant agents tend to produce segregated patterns because of the complexity of their local interactions and the snowball effect of individual moves on the global distribution of agents in the city. The main parameters of this model are the tolerance level (maximum % of agents different to ego accepted in the neighbourhood), the scope of sensing, the global majority/minority split and the percentage of vacant spaces in the housing market. In addition, we are interested in testing the impact of the initial spatial distribution of housing capacity in this project, using the generated grids.
The outcome of the model is measured by a combination of three segregation indices: Dissimilarity, Moran’s I and Entropy. The dissimilarity index (or Duncan’s D) is a global measure of segregation and the most widely used, although it does not account for local variations (White 1986; Brown & Chung 2006). It corresponds to the minimum percentage of the population who would have to move to another location so that the global area exhibits a uniform distribution of groups across its constituent areas (each small area would then display the same distribution as the area as a whole). Moran’s I is a spatial segregation index which denotes the overall spatial autocorrelation of a group. It takes positive values when a group is clustered in space (people of the same group as oneself are over-represented in the neighbourhood) and negative values when a group is dispersed (people of the same group as oneself are under-represented in the neighbourhood). Entropy can be used as an indicator of spatial segregation because it measures the evenness of groups distribution in space, although the metaphor of thermodynamics is not straightforward (Barner et al. 2017). In our case, areas with higher values of entropy are considered more segregated because the mix of groups is uneven across small areas, whereas low entropy denotes more uniform distributions.
We use an ad-hoc implementation of the Schelling model, both in Scala for performance reasons and in NetLogo to ensure visualization of model dynamics. The pseudo-code of the implemented model is available in Appendix E the source codes for both languages are available on the repository of the project at https://github.com/JusteRaimbault/SpaceMatters. In general, the implementations of Schelling models allow only one agent per cell, and their initial distribution is random, therefore following a uniform distribution across the modelled city. In this experiment, we allow more than one agent to be in a given cell. The potential density of a cell is defined by the density grid generated. If the potential density of a cell is not reached at initialisation, more agents can move into the cell during the course of the simulation, otherwise it is deemed full and unavailable for movers. The satisfaction and segregation indices are computed with regard to the people in the cell and the people present in neighbouring cells. Empirical distributions of density in cities are important in our framework because we want to test models with realistic ranges of initial patterns of density distribution. Therefore, we cannot limit ourselves to an isotropic square modelled city. We chose instead to use the actual distributions of European cities to constraint our density generation.
Sugarscape
Sugarscape is a model of resource extraction which simulates the unequal distribution of wealth within a heterogeneous population (Epstein & Axtell 1996). Although it "is designed to study the interaction of many plausible social mechanisms" (Axtell et al. 1996, p.125), we refer in this paper to the first (and simplest) version of the model, where "processes allow its agents to look for, move to, and eat a resource ("sugar") which grows on its [...] array of cells". Agents of different vision scopes and different metabolisms harvest a self-regenerating resource available heterogeneously in the initial landscape, they settle and collect this resource, which leads some of them to survive and others to perish. The main parameters of this model are the number of agents, their minimal and maximal resource levels. In an urban environment, Sugarscape can be used to model how the spatial distribution of any type of goods or services can influence the spread of wealth among inhabitants. Following Batty (2005), it can be considered as a metaphor of an urban system. We extend the implementation with agents wealth distribution of Li & Wilensky (2009). The outcome of the model is measured by a Gini index of inequality for resource distribution. We are interested in testing the impact of the spatial distribution of the resource, using the generated grids.
Experiment design
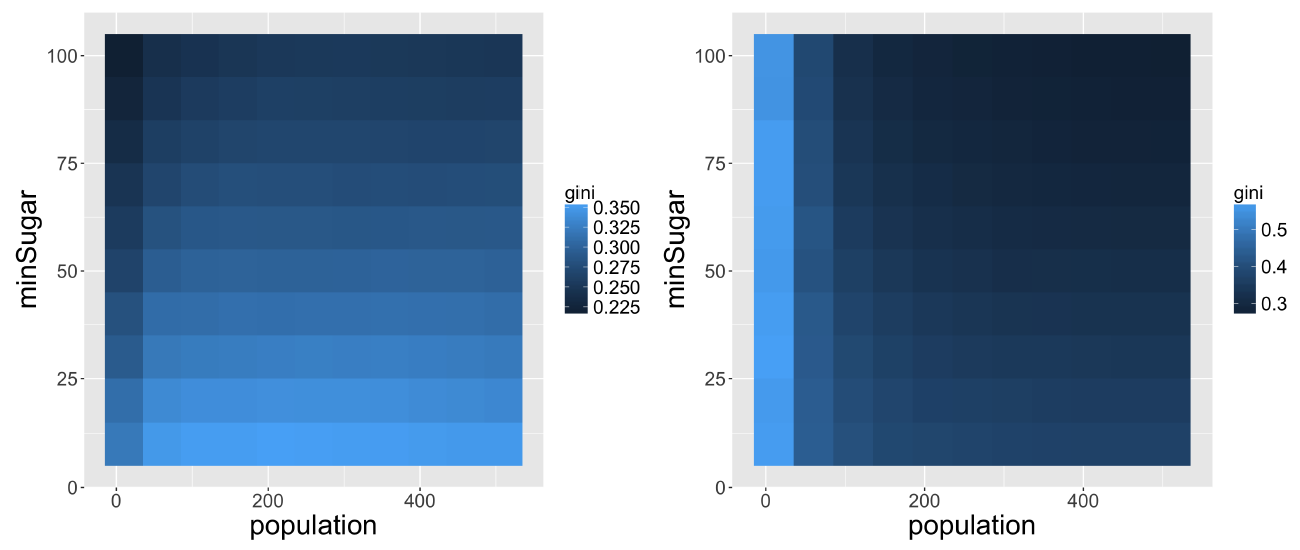
For Sugarscape, we explore three dimensions of the parameter space: the total population of agents \(P\in \left[10;510\right]\), the minimal initial agent resource \(s_{-}\in \left[10;100\right]\) and the maximal initial agent resource \(s_{+}\in \left[110;200\right]\). Each parameter is binned into 10 values, giving 1000 parameter points. We run 50 repetitions for each configuration, which yields reasonable convergence properties. The initial spatial configuration varies across 50 different grids, generated by sampling generator parameters in a LHS. We did not use the clustered grids to test the flexibility of our framework, which is demonstrated in this case by a direct sequential coupling of the generator and the model. Indeed, because the density distribution refers to the distribution of resource rather than to the representation of a city structure, we do not need the typology of urban density in this experiment. The full experiment thus equates to 2,500,000 simulations (1000 parameter combinations x 50 density grids x 50 replications).
For Schelling's model, we also explore three dimensions of the parameter space of the model: the minimum proportion of similar agents required in the neighbourhood for the agent to be satisfied (or intolerance level) \(S\in \left[0;1\right]\), the initial split of population, derived from the proportion of green population, \(G\in \left[0;1\right]\) and the vacancy rate of the city \(V\in \left[0;1\right]\). We sample 1000 parameter values using a Sobol sampling and run 100 repetitions for each configuration. We first try the same experiment design (50 density grids generated on the fly), then look at clustered grids representing urban densities. We choose 45 different grids among the ones which are most representative of the three types of urban morphology: 15 compact grids, 15 polycentric grids and 15 discontinuous grids. The last experiment thus equates to 4,500,000 simulations (1000 parameter combinations x 45 density grids x 100 replications). We use OpenMOLE to distribute the computation, and apply segregation measures to characterise the results.
As detailed in Appendix B, more repetitions are needed for Schelling indicators than for Sugarscape, in order to obtain a similar relative confidence in the estimation of averages. We run for this reason a different number of replications for each model. We choose different experiment designs, both for generator parameters and for the phase diagram, to demonstrate the robustness of the method to technical choices. In principle, our workflow applies regardless of the way we generate a spatial configuration (even taking real configurations) and the way we establish phase diagrams.
Results
The implementations of the models were done from NetLogo. We modified the Sugarscape version with wealth of NetLogo model library (to be able to explore it intensively) and we implemented from scratch the Schelling model. Both pseudo-codes are available in Appendix E, and source code for models, grid classification and simulation results analysis is available on the open repository of the project at https://github.com/JusteRaimbault/SpaceMatters. Density grids are also available at this address. Simulation data are available for reproducibility on the dataverse repository at https://doi.org/10.7910/DVN/9JI57U.
Sensitivity analysis
We measure the distance of the phase diagrams for all density grids with respect to the reference phase diagram computed on the default initial spatial condition setup (a bi-centric symmetrical non toroidal configuration) using the measure defined in Equation 1. For each density grid, we obtain the average squared distance between corresponding points of the phase diagrams, i.e. the mean value of the final output measure, such as segregation or inequality, for a given value of parameters in the two setups (isotropic and generated). This average squared distance for each point is then related to the average variance of each of the phase diagrams (the reference one and the one for the grid under inquiry). Therefore, values greater than 1 will mean that inter-diagram variability is more important than intra-diagram variability. We tested the sensitivity to the type of distance, using a Minkovski distance with a varying exponent. The results are presented in Appendix D, and show a similar sensitivity to geometric structures.
Sugarscape
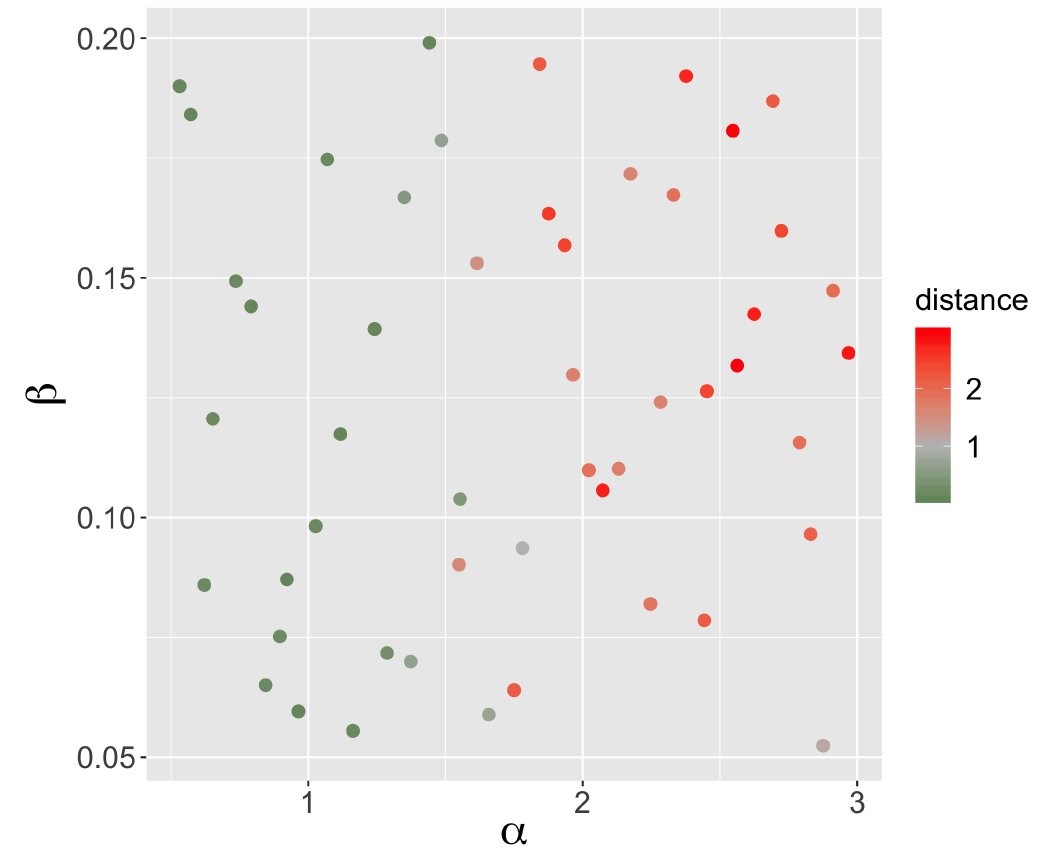
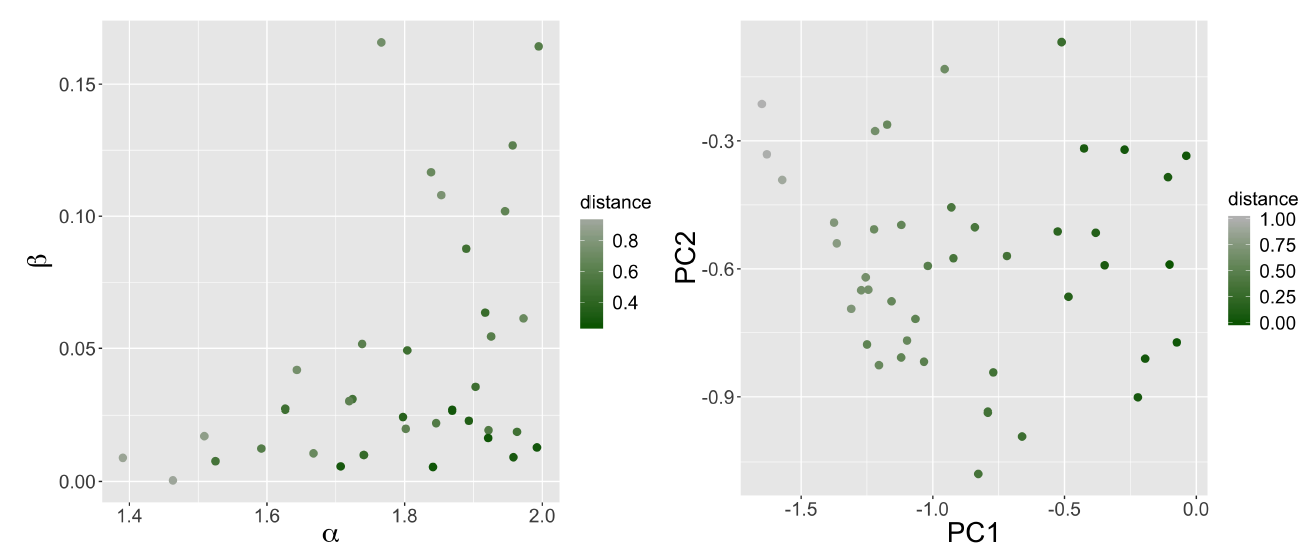
We obtain a very strong sensitivity to geometric structures for the Sugarscape model. Indeed, the relative distance between the phase diagrams of different density grids and the phase diagram of the reference case ranges from 0.09 to 2.98 with a median of 1.52 and an average value of 1.30. The mean distance above 1 means that, on average, the model is more sensitive to the generator parameters than to its own parameters (population and sugar endowment) in the reference model. Moreover, the maximum distance of 2.98 means that the variation due to the change of grid can be up to three times bigger than the variation due to the model parameters. We plot in Figure 4 the distribution of these distances in the generator parameter space. Each point represents one of the 50 different density grids used to initialise the distribution of sugar in the model. The points are projected with respect to the generator parameters, and coloured according to the relative distance of the phase diagram of the simulations using this grid to the phase diagram of the reference case. Therefore, Figure 4 shows that the grids generated with a high \(\alpha\) (i.e. with a small number of very high density cells) produce simulation results that vary more between the reference case and the generated grid with the same values of parameters than within the reference case because of parameter variations. This pattern is emphasized when grids are generated with a high \(\alpha\) and a high \(\beta\) (i.e. with low gradient of density decrease around the kernels of high density). These grids have the highest relative distance to the reference case. On the contrary, with grids closer to the uniform pattern of the reference case (bottom left of the graph), the model parameters are more important in determining the final inequality levels than the initial spatial distribution of sugar.
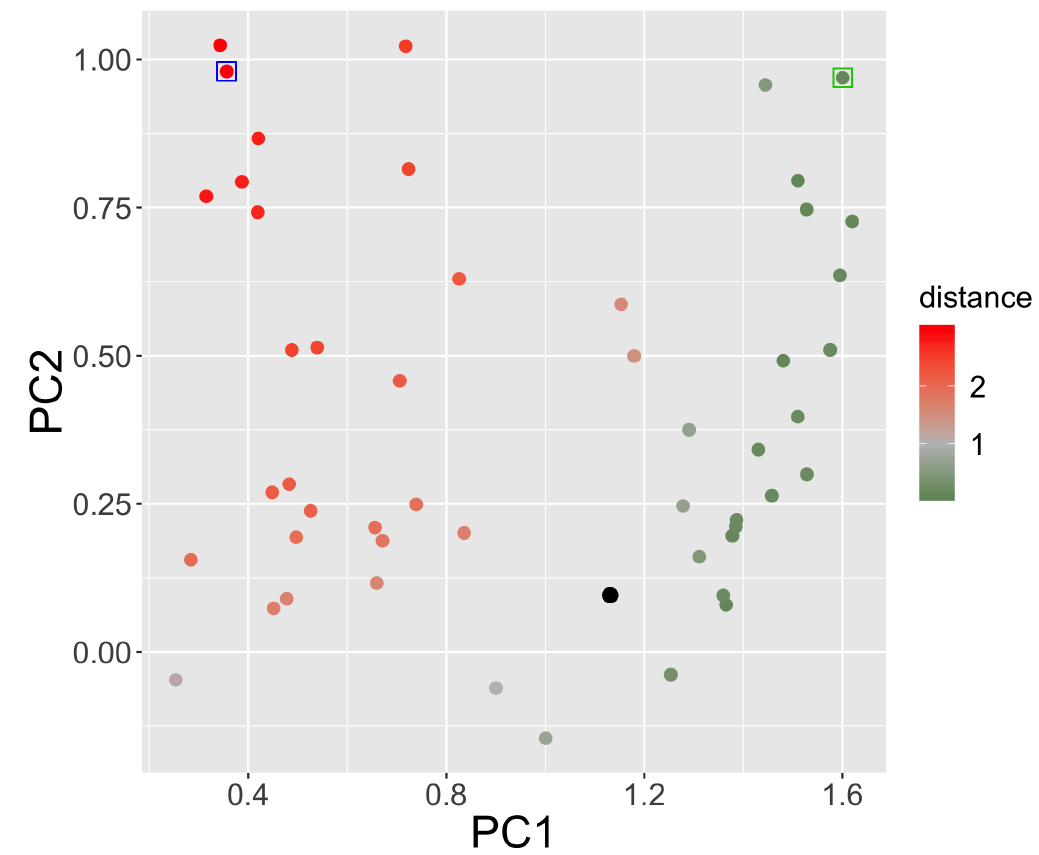
Another way of quantifying the density grids, instead of looking at the generator parameters, is to look at the resulting indicators of urban form, such as Moran’s I, average distance, rank-size slope and entropy (see Le Néchet (2015) for precise definition and context). This 4-dimensional space defined a morphological space. For the purpose of interpretability and visualisation, we reduce this space to a bi-dimensional space with a principal component analysis. The first two components represent 92% of cumulated variance. The first component defines a “level of sprawl” and of scattering, whereas the second one represents the level aggregation.[1] We find that grids producing the highest deviations are the ones with a low level of sprawl and a high aggregation (top left of Figure 5). It is confirmed by the behaviour as a function of generator parameters, as high values of \(\alpha\) also yield high distance. In terms of model processes, it shows that congestion mechanisms in the gathering of the resource induces fast increases of inequality. To put these results in perspective with our workflow given in Figure 1, we have a sensitivity to spatial parameters on average greater than the sensitivity to model parameters.
Schelling
Within a standard Schelling model (i.e. initialised with a uniform density grid), Gauvin et al. (2009) have built the phase diagram of segregation patterns depending on the combination of parameter values. For high levels of tolerance (S < 0.25), there is no segregation. For high values of vacancies (V > 0.65) and low values of tolerance (S > 0.5), there is a diluted segregation state where homogeneous communities are separated from others by large empty buffers. Finally, for low values of vacancies (V < 0.2) and low values of tolerance (S > 0.7), the model is frozen in a state where everyone is unhappy but no-one can express its intolerant behaviour due to the lack of free spaces. Between these extreme cases, the model gives rise to segregated states where homogeneous communities adjoin one another. The objective of this quantitative experiment is to evaluate to which extent this phase diagram is modified when different density grids are applied. We show in Figure 8 (Supplementary Material) the values of the relative distance as a function of generator parameters and in the reduced morphological space, in a way similar to the analyse done with Sugarscape. Variations are less considerable than for Sugarscape across phase diagrams, but values close to 1 show that several configurations are as sensitive to initial spatial conditions than to their parameters. We focus in the following on a qualitative characterisation of these variations.
Variation by type of structure
Schelling
In this qualitative exploration of the effect of initial spatial conditions on the results of Schelling’s model, we use the classification of grids into three morphological types (cf. Figure 3). In particular, we want to evaluate to which extent the typology summarises the spatial effects, and if one type of urban form or another enhances the segregation mechanism of the model, or interacts differently with the model parameters. This experiment attempts at drawing conclusions on urban morphology, beyond the technical conclusions already obtained with respect to simulation sensitivity.
In Table 1, we see that the type of density grid with which the model is initialised correlates to a certain extent with the level of segregation measured at the end of the simulation run. Indeed, compared to the reference case of compact (monocentric) density patterns, polycentric grids produce more dissimilarity and entropy between the location of green and red agents. Discontinuous grids have the same effect, although attenuated. The results obtained with Moran’s I are opposite, because this index measures spatial autocorrelation at the global level and that compact cities have higher levels of global autocorrelation by construction. However, linear models with and without the type of density distribution yield the same coefficients for Schelling’s parameters V and S, the only exception being the vacancy rate V in the Moran’s I model with grid types, which becomes non-significant. The similarity of the coefficient in both cases means that the effect of the model’s parameters (and thus the mechanism by which agents of similar group cluster in space) is the same regardless of the distribution of density. The way polycentric and discontinuous density grid exhibit higher segregation is by allowing buffer zones of low density to surround pockets of homogeneity, which is impossible in a compact city, because everyone is at reach of everyone else. The buffering process confirms previous results obtained with network structures (Banos 2012) and supports the conclusion that space acts here on top of mechanisms rather than in interaction with them.
| Simulation outcome by segregation index: | Dissimilarity | Entropy | Moran’s I | |||
| Intercept | -0.212 *** | -0.141*** | -0.254*** | -0.208*** | -0.036*** | -0.061*** |
| Similarity Wanted (S) | 1.212*** | 1.212*** | 1.250*** | 1.250*** | 0.550*** | 0.550*** |
| quadratic term (S2) | -0.942*** | -0.942*** | -0.963*** | -0.963*** | -0.428*** | -0.428*** |
| Vacancy Rate (V) | 0.602*** | 0.602*** | 0.453*** | 0.453*** | -0.027*** | -0.027*** |
| Minority Index (%Maj - %Min) | 0.307*** | 0.307*** | 0.130*** | 0.130*** | -0.067*** | -0.067*** |
| Density Grid = Polycentric | 0.087*** | 0.052*** | 0.001*** | |||
| Density Grid = Discontinuous | 0.111*** | 0.068*** | 0.00 | |||
| Attraction generator parameter \(\alpha\) | -0.083*** | -0.053*** | 0.014*** | |||
| Diffusion generator parameter \(\beta\) | 0.323*** | 0.218*** | 0.017*** | |||
| R2 (%) | 30.6 | 34.7 | 24.1 | 25.6 | 23.9 | 24.0 |
| # of observations (sim. runs) | 2,106,000 | 2,106,000 | 2,106,000 | 2,106,000 | 2,106,000 | 2,106,000 |
| AIC | -70717.68 | -198748.2 | 208213.8 | 166048.8 | -4385990 | -4387816 |
Sugarscape
We now check the sensitivity in terms of qualitative behavior of phase diagrams. We show the phase diagrams for two very opposite morphologies in terms of sprawling, but controlling for aggregation with the same \(PC2\) value. These correspond to the green and blue frames in Figure 5. In terms of grid shapes, we observe that the difference between the two grids is mainly on average distance and entropy: in a nutshell, the first grid is much more dispersed and disorganised than the second. Although the behaviours are rather stable for varying s+, the initial maximum endowment in sugar, which means that the poorest agents have a determinant role in trajectories, the two examples have not only a very distant baseline inequality (the ceiling of the first 0.35 is roughly the floor of the second 0.3), but their qualitative behavior is also radically opposite: the sprawled configuration (green frame) makes inequalities decrease as population decreases and decrease as minimal wealth increases, whereas the concentrated configuration (blue frame) makes inequalities strongly increase as population decreases and also decrease with minimal weights but significantly only for large population values (Figure 6). In sprawled spaces, inequalities are thus fostered by a lack of minimal local resources, whereas population will drive inequality in concentrated spaces. The process is thus completely reversed depending on the grid chosen to run the model on, which would have significant impacts if one tried to draw policy recommendations from this model.
Discussion
We consider that the method presented in this paper holds great potential for strengthening socio-spatial models’ exploration. However, three limits and two areas of opportunities have still not been tackled.
Limits
Comparing phase diagrams
Comparing phase diagrams is as we saw not straightforward, and further developments of our method imply testing alternative methods for this particular point. For example, in the case of the Schelling model, an anisotropic spatial segregation index (giving the number of clusters found and in which region in the parameter spaces they are roughly situated) would differentiate strong phase transitions in the space of generator parameters. The use of metrics comparing spatial distributions, such as the Earth Movers Distance which is used for example in Computer Vision to compare probability distributions (Rubner et al. 2000), or the comparison of aggregated transition matrices of the dynamic associated to the potential described by each distribution, would also be potential tools. Map comparison methods, popular in environmental sciences, provide numerous tools to compare two dimensional fields (Visser & De Nijs 2006; Kuhnert et al. 2005). To compare a spatial field evolving in time, elaborated methods such as Empirical Orthogonal Functions that isolates temporal from spatial variations, would be applicable in our case by taking time as a parameter dimension, but these have been shown to perform similarly to direct visual inspection when averaged over a crowdsourcing (Koch & Stisen 2017). The transfer of methods used to compare sequences (Kruskal 1983) or time-series (Liao 2005) is a possible way to develop measures between phase diagrams. The higher dimension of the phase diagrams we study must however be considered with caution when transferring methods, in a way analog to the application of global sensitivity indexes to spatial data (Lilburne & Tarantola 2009). We can also note than more generally, this problem of comparing phase diagrams is a particular instance of the more generic issue of comparing patterns, which for example include unsupervised learning techniques (Hastie et al. 2009). The investigation of diverse approaches to systematically quantify differences between phase diagrams is an important potential development of our method.
Sensitivity of indicators to the geometry
While we investigated the sensitivity to geometry of models together with their indicators, a potential research direction is to study the dependence of indicators themselves to the spatial configuration. Indeed, the segregation indices are likely to be zoning, size or population density dependent (Wong 1997; Reardon & O’Sullivan 2004). Generating point data rather than a grid could help overcoming these issues, and appears as a promising direction for future research. This methodological claim is also interesting from theoretical and empirical views as point data may be used to construct egohoods (Hipp & Boessen 2013), i.e. a smooth definition of neighbourhoods as opposed to the commonly used non-overlapping units.
Platform constraints and docking challenges
An aspect that we have not touched upon in the article with respect to the sensitivity to initial spatial conditions is the importance of the modelling platform as a constraint in the formalisation of space. For example, spatial structure may be easier to implement as a raster rather than a vector in NetLogo models, which could influence the implementation choices of some non-experienced modelers. Its toroidal default setting might also have influenced the work of many modellers who did not question explicitly the representation of space. This issue is part of the docking challenge (Axtell et al. 1996) (i.e. checking if two models can produce the same results), but more generally, it involves a description of the model and its spatial requirements more detailed than what is currently the rule.
Opportunities and extensions
Reproducibility and applicability
We wish to underline the interest of adding sensitivity analysis of the geometry of space during the exploration of models. As we have observed for simple agent-based models, uncertainties in the initial distribution of the space on which agents will interact play a role on the variability in model outputs. This would certainly be even more important for more sophisticated models, with more types of agents and types of interactions, insomuch as agent-based models tend to be used in realistic, diverse settings. Indeed, regarding path-dependency which was part of issues motivating our approach, the models we studied are not path-dependent for the aggregated indicators (while the final agent configuration naturally is). We postulate that intrinsically non-ergodic models such as the one studied by Coupé et al. (2017) should be more sensitive to geometry. Therefore, we believe that for many applied problems, studying the specific variability of model outputs regarding the geometry of space would be important to assess the transferability of results in other urban settings.
This is especially important in the context of the increasing recognition of the complexity of urban space and of the role cities plays in various aspects of sustainability: modelling cities with agent-based models might become more frequent (Perez et al. 2016) and we argue it is important to account for the diversity of urban configurations when disseminating the results of any model in the planning community.
We think that the method could (and should) be applied to larger models including domain mechanisms and more empirical initialisation data, for example synthetic populations. The sensitivity analysis to initial spatial conditions could then be either a replication on the spatial allocation of the synthetic population, or a series of spatial permutations of the empirical spatial inputs. We want to foster this extension of our work by releasing the density grids also generated, as well as the generating workflow and the model implementation. They are available on the open repository of the project at https://github.com/JusteRaimbault/SpaceMatters. Future work could be done to compare these or generate grids with a larger morphological span, covering other typical urban forms that can be found in the world.
Another way to go would be to implement additional generators, such as social networks (Alizadeh et al. 2016) with localised agents, transportation networks generators (Raimbault 2018b), or coupled road network and population raster generators (Raimbault 2019). The particular density grid generator we used here is an example among possible others, and our methodological contribution is generic as it does not depend on which generator is chosen.
An emancipation opportunity for social sciences
As Pumain (2003) points out in an overview of complexity approaches in geography, transfer of models and concepts between disciplines may induce a transfer of corresponding assumptions. Geography and the social sciences in general have been strongly influenced by physics in the last decades, that beside their highly enriching impact (O’Sullivan & Manson 2015), may have softly imposed strong assumptions such as homogeneity and isotropy of space in basic models. We believe that a renewed approach on the role of space as we proposed, in other terms insisting that space matters, is an opportunity for social sciences to build their own stream of methodologies in the modelling domain.
This relates to relations between empirical, conceptual and modeling dimensions of quantitative research in social sciences, as coined by Livet et al. (2010). In our case, a contribution in the modeling domain aiming at extracting further knowledge on model behavior (sensitivity to geometrical context), may lead to questioning theoretical concepts and empirical definitions on which the model was based, such as for example the meaning of neighborhood, hence geometry of space.
Conclusion
After reviewing the extensive literature on spatial biases in statistical and simulation models, we presented a method to analyse the sensitivity of a simulation’s results to the initial spatial configuration. We did so by implementing a spatial generator whose output is used as input for the simulation model. We applied this approach to two textbook ABMs: Schelling and Sugarscape. With the Schelling experiment, we found that the different urban morphologies have an impact on interaction patterns, and that polycentric and discontinuous cities appear systematically more segregated than compact cities in terms of dissimilarity and entropy index. With Sugarscape, we show that the model is more sensitive to space than to its other parameters in the reference NetLogo implementation, both qualitatively and quantitatively: the amplitude of variations across density grids is larger than the amplitude in each phase diagram, and the behaviour of the phase diagram is qualitatively different in different regions of the morphological space. We think that this method has the potential to increase the arsenal of evaluation of socio-spatial models, in order to assess the sensitivity of models to their initial spatial conditions but also to learn about the impact of the urban form on social mechanisms.
Acknowledgements
The authors acknowledge the funding of their institutions and the EPSRC project number EP/M023583/1. Results obtained in this paper were computed on the vo.complex-system.eu virtual organization of the European Grid Infrastructure (http://www.egi.eu). We thank the European Grid Infrastructure and its supporting National Grid Initiatives (France-Grilles in particular) for providing the technical support and infrastructure. This work is part of DynamiCity, a FUI project funded by BPI France, Auvergne-Rhône-Alpes region, Ile-de-France region and Lyon metropolis.Notes
- We have \(PC1 = 0.76\cdot distance + 0.60\cdot entropy + 0.03\cdot moran + 0.24\cdot slope\) and \(PC2 = -0.26\cdot distance + 0.18\cdot entropy + 0.91\cdot moran + 0.26\cdot slope\)
Appendix
A: Behavior of the density grid generator
Figure 7 summarises the behavior of the density grid generator, according to parameters \((\alpha,\beta)\). To put it in a simple way, high values of \(\alpha\) give highly hierarchical configurations, and diminishing \(\beta\) increase the number of centers. Low values of \(\alpha\) give diffuse patterns, with however clear centers for a high diffusion. We do not discuss here the role of other parameters, but according to Raimbault (2018a), diffusion steps give smoother forms, and the rate between total population and the population increment at each step (which is equivalent to the total number of steps) is crucial to select non-stationary distributions that are closer to real configurations. Raimbault (2018a) also shows the existence of non-linear behaviors in some regions of the parameter space, so the description we gave here shall not be interpreted as a linear link between generator parameters and the morphological properties of the generated grids.
B: Additional statistical analysis
For both models we estimate the Sharpe ratios for each indicator by \(S(X) = \hat{\mathbb{E}}\left[X\right]/\hat{\sigma}(X)\) with standard estimators for average and standard deviation. The summary statistics of this ratio computed on repetitions for all parameter points are given in Table 2. Under the assumption of a normal distribution, the width of the confidence interval at level \(c\) is given by \(\left|\mu_+ - \mu_-\right| = 2\cdot \sigma \cdot z_{c} / \sqrt{n}\) where \(\sigma\) is the standard deviation, \(z_{c}\) is the quantile at which \(c\) is attained by the cumulative distribution, which is around \(1.96\) for a 95% confidence interval. This means that to obtain a confidence interval of width \(\kappa \cdot \sigma\), one needs a number \(n \simeq (4 / \kappa )^2\) of repetitions. This gives 64 repetitions for \(\kappa = 2\). As the Sharpe ratios are in general smaller for Schelling indicators than for Sugarscape, we take \(n = 50\) for Sugarscape and \(n = 100\) for Schelling to have a similar confidence in estimations.
| Model/Indicator | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
| Sugarscape/Gini | 2.343 | 14.413 | 20.993 | 20.098 | 26.208 | 49.808 |
| Schelling/Dissimilarity | 1.053 | 12.368 | 19.434 | 25.268 | 24.328 | 468.563 |
| Schelling/Entropy | 0.5458 | 8.2591 | 14.5112 | 17.0100 | 17.9372 | 244.3230 |
| Schelling/Moran | 0.0001 | 0.5554 | 0.7782 | 3.2724 | 3.8979 | 121.6829 |
C: Additional figures for the Schelling model
Figure 8 shows the phase diagrams distances as a function of generator parameters and morphological components, similarly to the Sugarscape model in main text. In absolute, this version of the Schelling model seems less sensitive to density grids than the Sugarscape model, as we do not obtain a high range of values here. We however obtain measures ranging from 0 to 0.85 with the Euclidian distance, what is however characteristic of a significant sensitivity to space.
D: Comparison of phase diagram with other distances
We describe here the tests done with other distances to compare phase diagrams. We tested normalized Minkovski distances, defined by \(d(x,y) = \left(\frac{1}{N}\cdot \sum_i \left|x_i - y_i\right|^{q}\right)^{\frac{1}{q}}\), for varying values of \(q\) from \(q = 1\) (Manhattan distance) to \(q = 10\), including \(q = 2\) (Euclidian distance) which is used in main text. The Table 3 gives the summary statistics of each distance computed on all initial configurations for the Schelling model. We naturally obtain smaller difference with the Manhattan distance but which remain significant (averages of 10% for the Schelling model and 40% for Sugarscape), and variabilities with higher values of the Minkovski exponent are much higher. These results confirm the high variability observed in main text with the Euclidian distance.
| q | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
| 1 | 0.00000 | 0.02838 | 0.06263 | 0.10608 | 0.16818 | 0.37018 |
| 2 | 0.0000 | 0.1520 | 0.2517 | 0.3107 | 0.4359 | 0.8155 |
| 3 | 0.0000 | 0.3709 | 0.5133 | 0.5860 | 0.7435 | 1.2930 |
| 10 | 0.000 | 2.083 | 2.431 | 2.380 | 2.713 | 3.664 |
| q | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
| 1 | 0.07184 | 0.13996 | 0.39816 | 0.42452 | 0.64751 | 1.13169 |
| 2 | 0.08909 | 0.19794 | 1.52272 | 1.29594 | 2.16371 | 2.98273 |
| 3 | 0.1025 | 0.2288 | 3.1495 | 2.5074 | 4.2718 | 5.5378 |
| 10 | 0.1540 | 0.4466 | 9.8757 | 7.6246 | 13.0550 | 16.8001 |
E: Pseudo-code for models
We give below the pseudo-code for the implementations we used of both Sugarscape (Figure 10) and Schelling (Figure 9) models. We recall that source code is openly available at https://github.com/JusteRaimbault/SpaceMatters. The pseudo-code is in the style of NetLogo code, which is already easily readable.


References
ALIZADEH, M., Cioui-Revilla, C. & Crooks, A. (2016). Generating and analyzing spatial social networks. Computational and Mathematical Organization Theory, (pp. 1–29). [doi:10.1007/s10588-016-9232-2]
ALLEN, P. & Sanglier, M. (1981). Urban evolution, self organisation and decision-making. Environment and Planning, 13, 168–183.
ANAS, A., Arnott, R. & Small, K. A. (1998). Urban spatial structure. Journal of Economic Literature, 36(3), 1426–1464.
ARRIBAS-BEL, D., Nijkamp, P. & Poot, J. (2016). How Diverse can Spatial Measures of Cultural Diversity be? Results from Monte Carlo Simulations on an Agent-Based Model. Environment and Planning A, 48(10), 2046-2066. [doi:10.2139/ssrn.2462417]
ARTHUR, W. B. (1994). Increasing Returns and Path Dependence in the Economy. Ann Arbor: University of Michigan Press.
AXTELL, R., Axelrod, R., Epstein, J. M. & Cohen, M. D. (1996). Aligning simulation models: a case study and results. Computational and Mathematical Organization Theory, 1(2), 123–141. [doi:10.1007/bf01299065]
AZIZ-ALAOUI, M. & Bertelle, C. (2009). From System Complexity to Emergent Properties. Berlin: Springer.
BAKKER, M., Post, V., Langevin, C. D., Hughes, J. D., White, J., Starn, J. & Fienen, M. N. (2016). Scripting MODFLOW model development using Python and FloPy. Groundwater, 54(5), 733-739. [doi:10.1111/gwat.12413]
BANOS, A. (2012). Network euects in Schelling’s model of segregation: new evidences from agent-based simulation. Environment and Planning B: Planning and Design, 39(2), 393–405. [doi:10.1068/b37068]
BARNER, M., Cottineau, C., Molinero, C., Salat, H., Stanilov, K. & Arcaute, E. (2017). Multiscale entropy in the spatial context of cities. arXiv preprint arXiv:1711.09817.
BATTY, M. (1971). Modelling cities as dynamic systems. Nature, 231(5303), 425–428. [doi:10.1038/231425a0]
BATTY, M. (2005). Agents, cells, and cities: new representational models for simulating multiscale urban dynamics. Environment and Planning A, 37(8), 1373–1394. [doi:10.1068/a3784]
BATTY, M. (2007a). Cities and Complexity: Understanding Cities with Cellular Automata, Agent-Based Models, and Fractals. New York: The MIT press.
BATTY, M. (2007b). Model cities. Town Planning Review, 78(2), 125–151. [doi:10.3828/tpr.78.2.3]
BENENSON, I., Omer, I. & Hatna, E. (2002). Entity-based modeling of urban residential dynamics: the case of Yaffo, Tel Aviv. Environment and Planning B: Planning and Design, 29(4), 491–512. [doi:10.1068/b1287]
BENENSON, I. & Torrens, P. M. (2004). Geosimulation: object-based modeling of urban phenomena. Computers, Environment and Urban Systems, 28(1-2), 1–8. [doi:10.1016/s0198-9715(02)00067-4]
BHAT, C. R. & Koppelman, F. S. (1999). Activity-based modeling of travel demand. In Handbook of transportation Science (pp. 35-61). Springer, Boston, MA. [doi:10.1007/978-1-4615-5203-1_3]
BROWN, L. A. & Chung, S.-Y. (2006). Spatial segregation, segregation indices and the geographical perspective. Population, Space and Place, 12(2), 125–143. [doi:10.1002/psp.403]
CARLEY, K. M. (1999). On generating hypotheses using computer simulations. Tech. rep., Carnegie-Mellon, Univ. of Pittsburg.
CASTELLANO, C., Fortunato, S.& Loreto, V. (2009). Statistical physics of social dynamics. Reviews of Modern Physics, 81, 591–646. [doi:10.1103/revmodphys.81.591]
COTTINEAU, C., Reuillon, R., Chapron, P., Rey-Coyrehourcq, S. & Pumain, D. (2015). A modular modelling framework for hypotheses testing in the simulation of urbanisation. Systems, 3(4), 348–377. [doi:10.3390/systems3040348]
COUPÉ, C., Hombert, J.-M., Le Néchet, F., Mathian, H. & Sanders, L. (2017). Modéliser les migrations et la colonisation de nouveaux territoires par les homo sapiens. In Peupler la Terre, Sanders, L., ed. PUFR. [doi:10.4000/books.pufr.10554]
EPSTEIN, J. M. & Axtell, R. L. (1996). Growing Artificial Societies: Social Science from the Bottom Up. New York: The MIT Press. [doi:10.7551/mitpress/3374.001.0001]
FILATOVA, T., Verburg, P. H., Parker, D. C. & Stannard, C. A. (2013). Spatial agent-based models for socio-ecological systems: challenges and prospects. Environmental Modelling & Software, 45, 1–7. [doi:10.1016/j.envsoft.2013.03.017]
FLACHE, A. & Hegselmann, R. (2001). Do irregular grids make a difference? relaxing the spatial regularity assumption in cellular models of social dynamics. Journal of Artificial Societies and Social Simulation, 4(4),6: https://www.jasss.org/4/4/6.html.
FOSSETT, M. & Dietrich, D. R. (2009). Effects of city size, shape, and form, and neighborhood size and shape in agent-based models of residential segregation: Are Schelling-style preference effects robust? Environment and Planning B: Planning and Design, 36(1), 149–169. 00026 [doi:10.1068/b33042]
FOTHERINGHAM, A. S. & Wong, D. W. S. (1991). The modifiable areal unit problem in multivariate statistical analysis. Environment and Planning A, 23(7), 1025–1044. [doi:10.1068/a231025]
GAUVIN, L., Nadal, J.-P. & Vannimenus, J. (2010). Schelling segregation in an open city: A kinetically constrained blume-emery-griuiths spin-1 system. Physical Review E, 81(6), 066120. [doi:10.1103/physreve.81.066120]
GAUVIN, L., Vannimenus, J. & Nadal, J.-P. (2009). Phase diagram of a schelling segregation model. The European Physical Journal B, 70, 293–304. [doi:10.1140/epjb/e2009-00234-0]
GELL-MANN, M. (1995). The Quark and the Jaguar: Adventures in the Simple and the Complex. London: Macmillan.
HAGEN-ZANKER, A. & Jin, Y. (2012). A new method of adaptive zoning for spatial interaction models. Geographical Analysis, 44(4), 281–301. [doi:10.1111/j.1538-4632.2012.00855.x]
HASTIE, T., Tibshirani, R. & Friedman, J. (2009). Unsupervised learning. In The elements of statistical learning (pp. 485-585). Springer, New York, NY. [doi:10.1007/978-0-387-84858-7_14]
HATNA, E. & Benenson, I. (2012). The Schelling model of ethnic residential dynamics: Beyond the integrated - segregated dichotomy of patterns. Journal of Artificial Societies and Social Simulation, 15(1), 6: https://www.jasss.org/15/1/6.html. [doi:10.18564/jasss.1873]
HEROLD, M., Goldstein, N. C. & Clarke, K. C. (2003). The spatiotemporal form of urban growth: measurement, analysis and modeling. Remote Sensing of Environment, 86(3), 286–302. [doi:10.1016/s0034-4257(03)00075-0]
HIPP, J. R. & Boessen, A. (2013). Egohoods as waves washing across the city: a new measure of "neighborhoods". Criminology, 51(2), 287–327. [doi:10.1111/1745-9125.12006]
HORRITT, M. & Bates, P. (2001). Effects of spatial resolution on a raster based model of flood flow. Journal of Hydrology, 253(1), 239–249. [doi:10.1016/s0022-1694(01)00490-5]
JARGOWSKY, P. A. (2002). Sprawl, concentration of poverty, and urban inequality. Urban sprawl: Causes, consequences, and policy responses, 39-72.
JESSOP, B., Brenner, N. & Jones, M. (2008). Theorizing sociospatial relations. Environment and Planning D: Society and Space, 26(3), 389–401. [doi:10.1068/d9107]
KOCH, J. & Stisen, S. (2017). Citizen science: A new perspective to advance spatial pattern evaluation in hydrology. PLOS ONE, 12(5), 1–20. [doi:10.1371/journal.pone.0178165]
KRUSKAL, J. B. (1983). An overview of sequence comparison: Time warps, string edits, and macromolecules. SIAM Review, 25(2), 201–237. [doi:10.1137/1025045]
KUHNERT, M., Voinov, A. & Seppelt, R. (2005). Comparing raster map comparison algorithms for spatial modeling and analysis. Photogrammetric Engineering & Remote Sensing, 71(8), 975–984. [doi:10.14358/pers.71.8.975]
KWAN, M. (2012). The uncertain geographic context problem. Annals of the Association of American Geographers, 102(5), 958–968. [doi:10.1080/00045608.2012.687349]
LAURIE, A. J. & Jaggi, N. K. (2003). Role of’vision’in neighbourhood racial segregation: a variant of the Schelling segregation model. Urban Studies, 40(13), 2687–2704. 00115. [doi:10.1080/0042098032000146849]
LE Néchet, F. (2015). De la forme urbaine à la structure métropolitaine: une typologie de la configuration interne des densités pour les principales métropoles européennes de l’Audit Urbain. Cybergeo: European Journal of Geography. URL http://cybergeo.revues.org/26753 .
LE Texier, M. & Caruso, G. (2017). Assessing geographical effects in spatial diffusion processes: The case of euro coins. Computer, Environment and Urban Systems, 61(A), 81–93. [doi:10.1016/j.compenvurbsys.2016.08.003]
LI, J. & Wilensky, U. (2009). Netlogo sugarscape 3 wealth distribution model.
LIAO, T. W. (2005). Clustering of time series data - a survey. Pattern Recognition, 38(11), 1857–1874.
LILBURNE, L. & Tarantola, S. (2009). Sensitivity analysis of spatial models. International Journal of Geographical Information Science, 23(2), 151–168. [doi:10.1080/13658810802094995]
LIVET, P., Müller, J. P., Phan, D., Sanders, L. & Auatabu, T. (2010). Ontology, a mediator for agent-based modeling in social science. Journal of Artificial Societies and Social Simulation, 13(1), 3: https://www.jasss.org/13/1/3.html. [doi:10.18564/jasss.1538]
OPENSHAW, S. (1983). From data crunching to model crunching-the dawn of a new era.
OPENSHAW, S. (1984). The Modifiable Areal Unit Problem. Norwich, UK: Geo Books.
O’SULLIVAN, D. & Manson, S. M. (2015). Do physicists have’geography envy’? And what can geographers learn from it? Annals of the Association of American Geographers, 105(4), 704-722. [doi:10.1080/00045608.2015.1039105]
PEREZ, P., Banos, A. & Pettit, C. (2016). Agent-based modelling for urban planning current limitations and future trends. In International Workshop on Agent Based Modelling of Urban Systems, (pp. 60–69). Springer. [doi:10.1007/978-3-319-51957-9_4]
PORTUGALI, J. (2000). Self-Organization and the City. Berlin: Springer-Verlag.
PUMAIN, D. (2003). Une approche de la complexité en géographie. Géocarrefour, 78(1), 25–31. [doi:10.4000/geocarrefour.75]
PUMAIN, D. (2006). Hierarchy in Natural and Social Sciences. Berlin: Springer-Verlag.
QUESNEL, G., Duboz, R. & Ramat, E. (2009). The virtual laboratory environment - an operational framework for multi-modelling, simulation and analysis of complex dynamical systems. Simulation Modelling Practice and Theory, 17, 641–653. [doi:10.1016/j.simpat.2008.11.003]
RAIMBAULT, J. (2018a). Calibration of a density-based model of urban morphogenesis. PLoS ONE, 13(9), e0203516. [doi:10.1371/journal.pone.0203516]
RAIMBAULT, J. (2018b). Multi-modeling the morphogenesis of transportation networks. In Artificial Life Conference Proceedings, (pp. 382–383). MIT Press. [doi:10.1162/isal_a_00073]
RAIMBAULT, J. (2019). An urban morphogenesis model capturing interactions between networks and territories. In The Mathematics of Urban Morphology, (pp. 383–409). Berlin: Springer. [doi:10.1007/978-3-030-12381-9_17]
REARDON, S. F., & O’Sullivan, D. (2004). Measures of spatial segregation. Sociological Methodology, 34(1), 121-162. [doi:10.1111/j.0081-1750.2004.00150.x]
REUILLON, R., Leclaire, M. & Rey-Coyrehourcq, S. (2013). Openmole, a workflow engine specifically tailored for the distributed exploration of simulation models. Future Generation Computer Systems, 29(8), 1981–1990. [doi:10.1016/j.future.2013.05.003]
RUBNER, Y., Tomasi, C. & Guibas, L. J. (2000). The earth mover’s distance as a metric for image retrieval. International Journal of Computer Vision, 40(2), 99–121.
RYBSKI, D., Ros, A. G. C. & Kropp, J. P. (2013). Distance-weighted city growth. Physical Review E, 87(4), 042114. [doi:10.1103/physreve.87.042114]
SAINT-JULIEN, T., Sanders, L. & Pumain, D. (1989). Villes et auto-organisation. Economica.
SALTELLI, A., Ratto, M., Andres, T., Campolongo, F., Cariboni, J., Gatelli, D., Saisana, M. & Tarantola, S. (2008). Global Sensitivity Analysis: The Primer. John Wiley & Sons. [doi:10.1002/9780470725184]
SCHELLING, T. C. (1969). Models of segregation. The American Economic Review, 59(2), 488–493.
SCHELLING, T. C. (1971). Dynamic models of segregation. Journal of Mathematical Sociology, 1(2), 143–186.
SCHWANEN, T., Dieleman, F. M. & Dijst, M. (2001). Travel behaviour in Dutch monocentric and policentric urban systems. Journal of Transport Geography, 9(3), 173–186. [doi:10.1016/s0966-6923(01)00009-6]
SCHWARZ, N. (2010). Urban form revisited—Selecting indicators for characterising European cities. Landscape and Urban Planning, 96(1), 29-47. [doi:10.1016/j.landurbplan.2010.01.007]
SINGH, A., Vainchtein, D. & Weiss, H. (2009). Schelling's Segregation Model: Parameters, scaling, and aggregation. Demographic Research, 21(12), 341-366. [doi:10.4054/demres.2009.21.12]
SMITH, D. L., Lucey, B., Waller, L. A., Childs, J. E. & Real, L. A. (2002). Predicting the spatial dynamics of rabies epidemics on heterogeneous landscapes. Proceedings of the National Academy of Sciences, 99(6), 3668–3672. [doi:10.1073/pnas.042400799]
SPIELMAN, S. & Harrison, P. (2014). The Co-evolution of Residential Segregation and the Built Environment at the Turn of the 20th Century: A Schelling Model. Transactions in GIS, 18(1), 25–45. [doi:10.1111/tgis.12014]
STAUFFER, D. & Solomon, S. (2007). Ising, schelling and self-organising segregation. The European Physical Journal B, 57(4), 473–479. [doi:10.1140/epjb/e2007-00181-8]
SUN, T. & Wang, J. (2007). A traffic cellular automata model based on road network grids and its spatial and temporal resolution’s influences on simulation. Simulation Modelling Practice and Theory, 15(7), 864-878. [doi:10.1016/j.simpat.2007.04.010]
THOMAS, I., Jones, J., Caruso, G., & Gerber, P. (2018). City delineation in European applications of LUTI models: review and tests. Transport Reviews, 38(1), 6-32. [doi:10.1080/01441647.2017.1295112]
TISUE, S. & Wilensky, U. (2004). Netlogo: A simple environment for modeling complexity. In International conference on complex systems, (Vol. 21, pp. 16-21).
TSAI, Y.-H. (2005). Quantifying urban form: compactness versus’ sprawl’. Urban Studies, 42(1), 141–161. [doi:10.1080/0042098042000309748]
VÁZQUEZ, R., Feyen, L., Feyen, J. & Refsgaard, J. (2002). Effect of grid size on effective parameters and model performance of the mike-she code. Hydrological processes, 16(2), 355–372. [doi:10.1002/hyp.334]
VECCHIOLA, C., Pandey, S. & Buyya, R. (2009). High-performance cloud computing: A view of scientific applications. In 2009 10th International Symposium on Pervasive Systems, Algorithms, and Networks, (pp. 4–16). IEEE. [doi:10.1109/i-span.2009.150]
VISSER, H. & De Nijs, T. (2006). The map comparison kit. Environmental Modelling & Software, 21(3), 346–358. [doi:10.1016/j.envsoft.2004.11.013]
WHEELER, C. H. (2006). Urban decentralization and income inequality: Is sprawl associated with rising income segregation across neighborhoods? FRB of St. Louis Working Paper, (No. 2006-037A). [doi:10.20955/wp.2006.037]
WHITE, M. J. (1986). Segregation and diversity measures in population distribution. Population index, 198-221. [doi:10.2307/3644339]
WILENSKY, U. & Rand, W. (2007). Making models match: Replicating an agent-based model. Journal of Artificial Societies and Social Simulation, 10(4), 2: https://www.jasss.org/10/4/2.html.
WILSON, A. (1981). Catastrophe theory and bifurcation: Application to Urban and Regional System. London: Croom Helm.
WILSON, A. (2002). Complex spatial systems: Challenges for modellers. Mathematical and Computer Modelling, 36(3), 379–387. [doi:10.1016/s0895-7177(02)00132-2]
WONG, D. W. S. (1997). Spatialdependency of segregation indices. Canadian Geographer, 41, 128–136.
WU, F. (2002). Complexity and urban simulation: Towards a computational laboratory. Geography Research Forum, 22, 22–40.