
Introduction
A key concept in managing complex systems is the segmentation of a system into distinct subsystems. This concept is employed, for example, in the context of product design in form of modularization (e.g., Baldwin & Clark 2000; Ethiraj & Levinthal 2004) as well as in the structuring of organizations by differentiation (Lawrence & Lorsch 1967) addressing issues like division of labor, task formation, delegation and specialization. However, the segmentation into subsystems – may it be, for example, sub-modules of a product or units (departments) within a firm – has to be accompanied by integration of the subsystems to make sure that the system as a whole accomplishes its task (Baldwin & Clark 2000). In the context of organizational structuring, integration is, for example, associated with coordination via hierarchies, incentives provided to managers for pursuing the overall objective of an organization or the sharing of norms (Lawrence & Lorsch 1967). Across such different scientific domains as (computational) organization theory, control theory or complex systems design to name but a few (e.g., Carley & Zhiang 1997; Galbraith 1974; Gross & Blasius 2008; Lawrence & Lorsch 1967; Yongcan et al. 2013), it is well recognized that the performance of an organization may be subtly affected by how it balances between differentiation and integration (e.g., Lawrence & Lorsch 1967; Horling & Lesser 2004; Lesser 1991; Lesser 1998).
Notwithstanding the various “schools” of organizational thinking, limitations in knowledge, communication and information-processing capabilities could be regarded as essential reasons for differentiation – may it be to make use of better information due to more specialized knowledge of subordinate managers, to parallelize and, by that, speed up problem-solving or in order to relieve the headquarter from certain tasks and, thus, avoiding its information overload (see, for example, (Galbraith 1974; Sah & Stiglitz 1986; Marengo et al. 2000; Colombo & Delmastro 2004). However, differentiation also has its downside with respect to problem-solving: With a higher number of subsystems, each subsystem has a decreasing scope of competence and, hence, an even more limited perspective on the overall task to be accomplished which raises the need for integration. Generally speaking, the number of subsystems – and the number of agents employed accordingly – affects the trade-off between capacity for problem-solving and the need for coordination in the system (e.g., Lawrence & Lorsch 1967; Van De Ven et al. 1976; Yongcan et al. 2013; Lesser & Corkill 2014).
Against this background, finding the appropriate segmentation into subsystems is a key issue, and, with this, the concept of the environment comes into play. A central idea is that the structural complexity of a system is to be aligned with its environmental complexity, (e.g., Galbraith 1973; Carroll & Burton 2000; Siggelkow & Rivkin 2005): Environmental complexity addresses the number and interrelatedness of “elements” an organization has to deal with simultaneously and, in particular, characterizes an organization’s task environment (Lawrence & Lorsch 1967; Anderson 1999; Sorenson 2002); structural complexity is affected by the level of an organization’s differentiation into subsystems and the mechanisms for integrating (coordinating) the sub-systems in order to achieve the organization’s overall objectives (Lawrence & Lorsch 1967). In other words, according to this idea, two properties are of relevance for achieving an appropriate differentiation: (1) inherent in the overall task to be accomplished, there is a certain task complexity in terms of interactions among the task’s elements which captures the “real” nature of the task (task environment); (2) the structural complexity – as deliberately shaped by differentiation and integration – is to be aligned to the task environment.
For this alignment, an obvious idea is to structure an organization into distinct subsystems such that it mirrors the underlying “real” structure of the task, i.e., the interactions among its elements (Baldwin & Clark 2000; Henderson & Clark 1990). However, the underlying “real” task obviously does not have to be fully decomposable in the sense that there are merely subtasks with dense intra-subtask, but no cross-subtask interactions (Simon 1962; Baldwin & Clark 2000). Hence, without full decomposability the straightforward idea of mapping the task’s structure to a corresponding, i.e., “isomorphic” structure of subtasks – each of which distinctly assigned to one unit within the organization respectively – becomes more intricate: then choices made by one subsystem related to its subtask may (detrimentally) affect the performance of other subsystems related to their particular subtasks (Wood 1986; Baldwin & Clark 2000; Ethiraj & Levinthal 2004).
It has been argued that task complexity and its relation to structural complexity requires further research, (e.g., Hærem et al. 2015; Lesser & Corkill 2014). Among the issues raised is that task complexity does not necessarily need to be stable over time and that the task complexity may not in all cases shape the communication patterns required for integration accordingly. In this context, an interesting question is whether, for shaping the appropriate organizational structure, the task complexity in terms of the “real” interaction structure among the task’s elements is known in advance to the designer of an organization. For example, after a firm has gone through some external shock which has affected the firm’s task environment, there might be rather limited knowledge of the “real” task complexity. Hence, an interesting question is which differentiation emerges when an organization – in the search for superior performance for a given, though not perfectly known task – learns and adjusts its structure and, thus, self-adaptively balances the trade-off between its subsystems’ capacity and competencies of problem-solving.
This paper seeks to contribute to this particular field of research and studies situations where the complexity of the underlying problem to be solved is not known to the designer of the organization in advance. In particular, the paper deals with the question which task formations in the organizational structure emerge for different levels of task complexity. For this, the study employs an agent-based simulation with the agents having imperfect foresight and limited information-processing capabilities. In particular, the study focuses on the following research question:
- The aforementioned prominent idea of isomorphism - i.e., structural complexity mirroring task complexity - leads to the conjecture that over time isomorphism emerges. Hence, in case of a decomposable "real" structure of a task this lets one expect that the emerging formation into subsystems reflects this "real" structure.
- Since the “real” structure of tasks may not be perfectly decomposable, it is interesting to investigate the sensitivity of the formation into subsystems emerging towards increasing levels of task complexity.
- Given the core issues of organizational structuring, i.e., differentiation and integration, an interesting question is, whether the emergence of formation into subsystems is sensitive to the mechanisms employed for integration.
With the latter aspect, the study takes into account, that the mechanisms of coordination may allow for different levels of decomposition into subsystems (e.g., with more intense coordination a higher level of segmentation might be feasible). However, it is worth mentioning that this study focuses on the task formation in terms of decomposition of an organization's task; yet, the study does not address the task allocation to potentially heterogeneous agents which would require to deal with the question of which tasks are assigned to which particular agents.
For the purpose of this study, an agent-based simulation model is employed which is based on the framework of NK fitness landscapes as suggested in evolutionary biology (Kauffman & Levin 1987; Kauffman 1993) and, since then, employed in rather different contexts in managerial science (for an overview see, for example, Wall 2016). A major advantage of the NK model is that it allows to systematically vary the complexity of a search problem in terms of the interdependencies among its subproblems (Li et al. 2006), and this feature obviously makes it a functional basis for the research questions of this study. In the simulations, learning organizations search on NK fitness landscapes for higher levels of performance and – from time to time – may modify the task formation and, with this, the number of units established for accomplishing the respective subtasks.
The paper is organised as follows: Subsequently, the simulation model is introduced. Section 3 gives a short overview over the simulation experiments conducted and the respective scenarios simulated. In Section 4 results are presented and discussed.
Simulation Model
The simulation model is introduced according to the ODD protocol proposed by Grimm et al. (2006; see also Grimm et al. 2005; Polhill et al. 2008). With that, after giving an “Overview” the model description reports on “Design concepts” and presents in the “Details”, in particular, the modes of coordination and learning captured in the model.
Overview
Purpose
The very core of this simulation study boils down to the question which task formation and, in consequence, which number of problem-solving agents emerges for which interaction structure among the elements of an overall task that an organization seeks to accomplish. The simulation model depicts artificial organizations facing decision problems of different levels of complexity and allows to study the task formations which emerge based on reinforcement learning. The study controls for different modes of coordination among the agents involved in decision-making.
State variables and scales
The model comprises three main building blocks: (1) the \(N\)-dimensional decision problem with the interaction structure among the \(N\) single choices \(d_i\); (2) the decision-making agents, their tasks, and the mode of coordination; (3) learning by reinforcement about task formation. Table 1 summarizes the related variables and parameters.
(1) N-dimensional decision problem and the decisional interactions. As mentioned in the introduction, this study employs the framework of NK fitness landscapes (Kauffman 1993 ). In the model presented here, parameter \(N\) captures binary decisions \(d_{it}\) with \(i=1,...,N\) to be made within a certain time step \(t\). Each of the two states \(d_{it}\in \left\{0,1\right\}\) contributes with \(C_{it}\) to the overall objective of the organization. Subsequently, the term "performance" is used to capture in how far the overall objective of an organization is achieved - though not fixing what this objective may be. Hence, the term "performance" could refer to "classical" financial objectives (e.g., profit) or, for example, to ecological objectives. Contributions \(C_{it}\) are randomly drawn from a uniform distribution with \(0\leq{C_{it}}\leq1\) though controlled by the complexity of the underlying search problem as captured by parameter \(K\) which reflects the interdependencies among the \(N\) single choices. In particular, \(K\) denotes the number of choices \(d_{jt}\), \(j\neq{i}\) which also affect contribution \(C_{it}\) of choice \(d_{it}\). In case of no interactions, \(K\) is \(0\); at a maximum level of interactions, \(K\) equals \(N-1\), meaning that every single option \(d_{it}\) affects contributions of all other options and vice versa. Hence, subject to \(K\), contribution \(C_{it}\) might not only depend on the single choice \(d_{it}\), but also on \(K\) other choices \(d_{jt}\) where \(j\in \left\{1,...N\right\}\) and \(j\neq{i}\):
| $$C_{it}=f_{i}({d_{it},d_{jt}),j\in\left\{1,..., i-1, i+1,...,N\right\}}.\label{contrib}$$ | (1) |
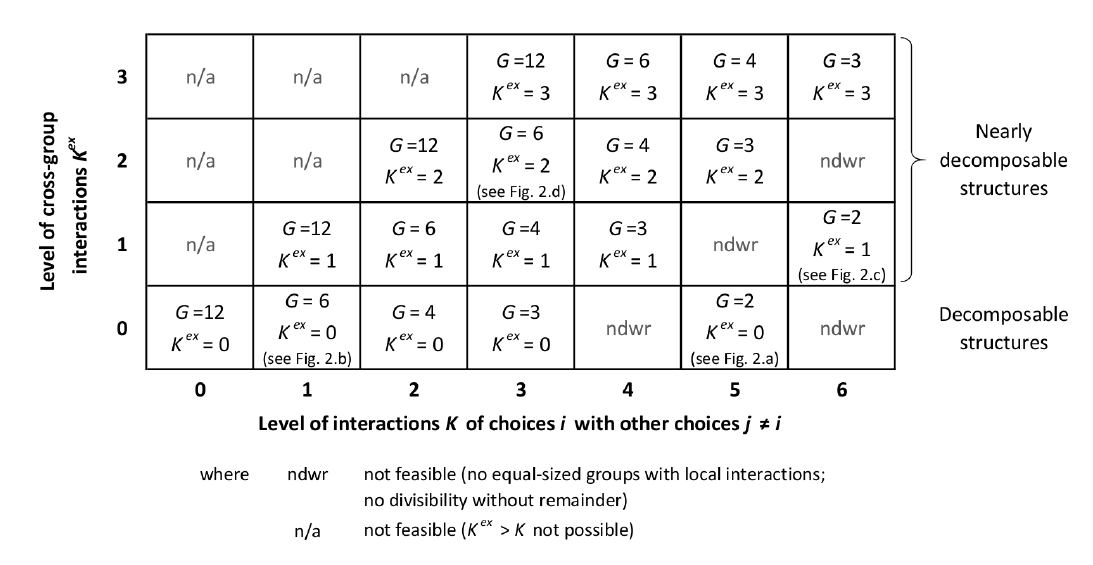
The simulation experiments are conducted for an \(N=12\)-dimensional decision problem and, thereby, according to the NK framework, in sum \(5.44452\cdot10^{39}\) different interaction structures are possible[1]. Apart from the level \(K\) of interactions among decisions, this simulation study also considers the decomposability of an overall decision problem. For this, the number of sub-groups \(G\) of decisions \(d_{it}\) with intense intra-group interactions and the level \(K^{ex}\) of cross-group interactions are helpful parameters. The particular interaction structures (characterized by parameters \(K\), \(G\) and \(K^{ex}\)) which are reflected in the simulation experiments are introduced in Section 3. For now, to give an example for an overall problem which could be decomposed into distinct problems think of an organization like a holding company with very different investments (e.g., power plant and baby food) without notable interactions among them. In contrast, a car manufacturer faces rather complex decisional problems in terms of interactions among decisions: for example, when developing a new engine it is relevant that an engine can be used in different models while however other design options as well as the positioning in the market are affected by the engines used and, conversely, affect features of an appropriate engine.
(2) Tasks, agents and the mode of coordination. The model comprises organizations with two types of agents: the headquarter and the units in terms of departments. All units are residing at the same hierarchical level directly below the headquarter and each unit has a head (manager) which is in primary control of decision-making. However, the model does not distinguish between the unit and its head and, hence, subsequently, only the units are addressed. Whether the headquarter intervenes in the decision-making on the \(N\)-dimensional decision problem (or is confined to, for example, just observing the level of performance achieved) depends on the mode of coordination employed (see Section "Submodels"); however, the headquarter is in charge of deciding on the task formation (see Sections 2.9, 2.26 to 2.27). The \(N\)-dimensional search problem is (endogenously) partitioned into \(M_t\) disjoint partial problems \(\vec{d}_t^r\) of equal size[2] of \(N^{*}_{t}= {N}/{M_t}\) binary choices and each subtask is exclusively assigned to one unit \(r\in\left\{1,...,M_t\right\}\). Hence, at time step \(t\) each unit \(r\) has primary control over a subset of \(N^*_t\) single choices of the \(N\) choices[3].
Apart from the choices \(d_{it}\) assigned to them, the units are also characterized by a certain level of competence, captured by \(\sigma^{r}\), which reflects how precisely a unit is capable to ex ante assess the consequences of its decisions. In particular, distortions from the true consequences of an option are depicted by adding a relative error (for other functions see Levitan & Kauffman 1995). The respective error terms follow a Gaussian distribution \(N(0;\sigma)\) with expected values \(0\) and the standard deviations \(\sigma^{r}\) being assumed to be the same for each unit \(r\); errors are assumed to be independent from each other. Hence, each unit \(r\) has a distinct view of the "true" performance landscape and, thus, units are heterogeneous in this respect - although for simplicity's sake they operate with the same error levels (Wall 2010). In the simulation experiments the error level is set to 0.1. There is some empirical evidence that this could be a realistic estimation of the error level of decision-making in organizations (Tee et al. 2007; Redman 1998).
The simulation experiments are carried out for different modes of coordination (\(coord\)) among the units which are introduced within the Section on “Submodels”. In one of these modes, the headquarter intervenes in decision-making. In this case, the headquarter's precision of assessment, \(\sigma^{head}\), is relevant too. In order to reflect the difference between the more specialized competence on the departmental site (as captured by \(\sigma^{r}\)) compared to the broader, though less specialized competence of the headquarter, \(\sigma^{head}\) is set to 0.15.
(3) Reinforcement Learning. The artificial organizations are endowed with learning capabilities captured by a simple form of reinforcement learning. Within the entire observation period \(T\) in every \(T^*\)-th period the headquarter learns about the success of the current configuration \(M_t\) of subtasks. Details on the form of reinforcement learning implemented in this study are introduced in the section on "Submodels" (see Sections 2.26 to 2.27).
| Variables | Brief description | Values |
| ... for characterizing the decision problem and interactions among decisions | ||
| \(d_{it}\) | Binary choice \(i\) in time step \(t\) | 0 or 1 |
| \(N\) | Number of decisions \(d_i, i=1,...,N\) | 12 |
| \(C_{it}\) | Contribution of binary choice \(i\) in time step \(t\) to the organization's objective | \(\in\mathbb{R}\) with \(0\leq{C_{it}}\leq1\) |
| \(K\) | Level of interactions among decisions | 0 to 5 |
| \(G\) | Number of groups of subproblems with intense interactions among intra-group decisions | 2, 3, 4, 6 and 12 |
| \(K^{ex}\) | Level of cross-group interactions among decision | 0 to 3 |
| ... for characterizing tasks, agents and the mode of collaboration | ||
| \(M_t\) | Number of subtasks or units, respectively \(r=(1,...,M_t)\) at time-step \(t\) | 2, 3, 4 or 6 |
| \(N^*_t\) | Number of binary choices assigned to units \(r=(1,...,M_t)\) | 2, 3, 4 or 6 |
| \(coord\) | Mode of coordination among units | “decentralized”, “sequential” or “proposal” |
| \(\sigma^{r}\) | Level of information precision of unit \(r\) | 0.1 |
| \(\sigma^{head}\) | Level of information precision of the headquarter | 0.15 |
| ... for reinforcement learning | ||
| \(T\) | Observation period | 500 |
| \(M^{a}\) | Option \(a\) out of a set \(A\) of feasible options of numbers of subtasks or units, respectively | \(A=\left\{2,3,4,6\right\}\) |
| \(p(M^{a},t)\) | Probability of option \(a\) of number of sub-tasks, or unit respectively, to be chosen at time step \(t\) | \(0\leq{p(M^{a},t)}\leq1\) |
| \(v_0\) | Aspiration level in time step \(t=0\) | 0 |
| \(b\) | Speed of adjustment of \(v_t\) | 0.5 |
| \(\lambda\) | Learning strength | 0.5 |
Process overview and scheduling
Figure 1 depicts the principle processual structure of the simulation model and Figure 10 in Appendix A illustrates the processes of the model in a flow chart more into detail. The key structure of the simulation is captured by two loops which differ in their temporal horizon: In the short term, in each time step \(t\) the artificial organizations search for superior solutions of their \(N\)-dimensional decision problem where the overall problem is segmented into \(M_t\) and delegated to \(M_t\) problem-solving units accordingly. In the mid-term, i.e., in each \(T^*\)-th time step, the organizations evaluate the current task formation captured by \(M_t\), learn from this evaluation via reinforcement and, eventually, choose another task formation for the next \(T^*\) periods.
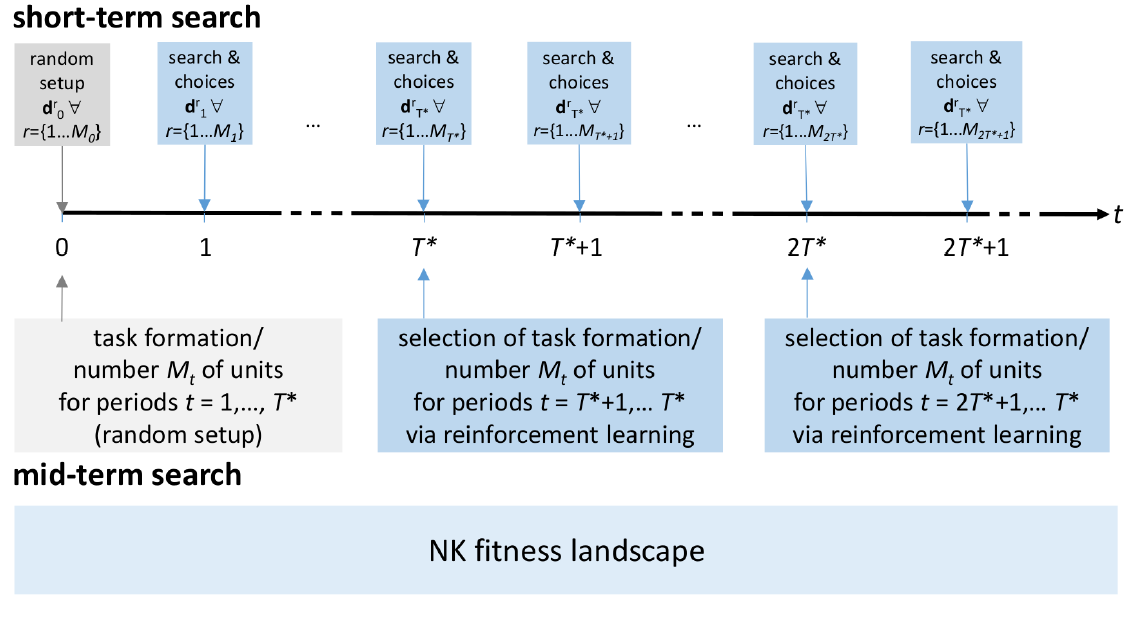
Design concepts
Emergence: The model is designed to study the emergence of task formation in organizations. The task formation is captured by the number \(M_t\) of tasks and, correspondingly, of units to which the tasks are assigned, and, in a nutshell, the emergence of number \(M_t\) of tasks (units) is in the focus of this simulation study. The emergence of the task formation results from the organizations' learning about which task formation leads to sufficient performance enhancements. Performance enhancements, in concrete, are achieved by the adaptive search of units for superior solutions to their particular subtasks as shaped by the task formation.
Fitness/Objectives: The overall performance level achieved by the organization as a whole with a certain configuration \(\vec{d_t}={(d_{1t},...,d_{Nt})}\) of the overall decision problem at time step \(t\) is - in line with the NK framework (Kauffman & Levin 1987), (Kauffman 1993)-- defined as the normalized sum of contributions \(C_{it}\) (see Equation 1):
| $$V_{t}=V(\vec{d_t})=\frac{1}{N}\sum^{N}_{i=1} {C_{it}}.\label{overallperf}$$ | (2) |
| $$P^{r}_{t}(\vec{d}^r_t)=\frac{1}{N}\sum^{rN^r_t}_{i=1+(r-1)N^r_t} {C_{it}}\label{agentperf}$$ | (3) |
Interactions: The model captures two types of interactions among units. (1) Indirect interactions through interdependencies captured by levels \(K\) and \(K^{ex}\): Whether choices made by unit \(r\) affect the performance resulting from choices of unit \(q\neq r\), depends on the interaction structure among the single choices \(d_i\) as reflected in functions \(f_i\) (Equation 1), and on the task formation. In case that “cross-task” interdependencies exist (i.e., \(K^{ex}>0\)), the individual objective functions (Equation 3) do not necessarily complement each other with respect to the overall performance (Equation 2) which is, in line with the NK framework, shaped by the randomly chosen \(C_i\) (Equation 1). (2) Direct interactions depending on the mode of coordination: The model captures different modes of how the decision-making units collaborate with each other and, in particular, how the final choices on the \(M_t\) partitions of the overall decision problem are aligned and how the headquarter comes into play. These modes of coordination are introduced more into detail in the Section on submodels (see 2.22 to 2.25).
Adaptation: As aforesaid, the simulation model comprises two intertwined adaptive processes with different time horizons (Figure 1): (1) In the short term the \(M\) units seek to find superior levels of performance with respect to their individual objectives (Equation 3). In every time step \(t\), each of the \(M_t\) units seeks to find a superior solution for its "own" partial decision problem \(\vec{d_t^r}\) of the overall problem while, so far, assuming that the other units do not alter their prior choices. For this, unit \(r\) randomly discovers two alternatives of its partial vector to status quo \({\vec{d}^{r*}_{t-1}}\): an alternative configuration that differs in one of the binary choices (\(a1\)) and another (\(a2\)) where two bits are flipped compared to the status quo. With this, in time step \(t\), unit \(r\) has three options to choose from, i.e., keeping the status quo or switching to \({\vec{d}^{r,a1}_{t}}\) or \({\vec{d}^{r,a2}_{t}}\). Each unit \(r\) forms its preferences out of these and prefers that option most which promises the highest performance \(P^r_t\). (2) In the mid term the organization may adapt the task formation via learning by reinforcement which is introduced more into detail in the Section on submodels (see 2.26 to 2.27).
Prediction: The three options, \({\vec{d}^{r*}_{t-1}}\), \({\vec{d}^{r,a1}_{t}}\), and \({\vec{d}^{r,a2}_{t}}\), from which each unit has to choose in time step \(t\), are evaluated regarding the consequences for that particular unit's individual objective function (Equation 3). The units know the true performance \(P^{r}_{t}({\vec{d}^{r*}_{t-1}})\) that has been achieved with the status quo (for example, because they have been compensated accordingly). However, units are not necessarily capable to perfectly evaluate the performance \(P^{r}_{t}\) as given in Equation 3 of the newly discovered options \(a1\) and \(a2\), i.e., the units may misjudge these options' contributions to objective \(P^{r}_{t}\). These misjudgements may, for example, result from incomplete knowledge (expertise) or from limited information-processing capabilities for assessing performance effects of the \(\vec{d}^r_t\). In the simulation model, distortions are depicted by the adding an error which reflects a relative error to true performance (see Section 2.7, i.e.,
| $${\tilde{P}^{r}_{t}(\vec{d}^r_t)={P}^{r}_{t}({\vec{d}^r_t})+{e}^{r}({\vec{d}^r_t})}\label{disagentperf}$$ | (4) |
Sensing: The agents captured in the model, i.e., the units as well as the headquarter, have incomplete knowledge in several aspects:
- As familiar in agent-based modelling, the agents are not able to overlook the entire solution space and the fitness landscape at once, and, thus, are not able to identify the best solution "instantaneously''; rather, they have to search stepwise for superior solutions (Simon 1955; Simon 1962). The units' capabilities for search are limited to finding two alternatives (i.e., \(a1\) and \(a2\)) to the status quo per time step.
- The headquarter's as well as the units' memory is limited: They know which configuration \(\vec{d^*_{t-1}}\) has been implemented in the previous period, but they do not remember which configurations have been realized in periods prior than \(t-1\).
- When, in each time step \(t\), first forming their preferences, units guess that the other units stay with their particular choices made in the previous period; only in the course of coordination (see Sections 2.22 to 2.25) and the, eventually, mutual adjustment of plans they may take the recent plans of other units into account. This, however, is subject to the particular mode of coordination.
Stochasticity: The model comprises some stochastic elements:
- In line with the NK framework, the contributions \(C_i\) (see Equation 1) - though controlled by the interaction structure - are drawn from a uniform distribution \(\left[0;1\right]\).
- The initial task formation as well as the initial "position" of an organization in the performance landscape is chosen randomly.
- The units - not able to perform an optimization, but confined to a satisficing approach employing stepwise search - in every time step \(t\), discover the two alternative partial solutions (\(a1\) and \(a2\)) compared to the status quo at random.
- The prediction of these alternatives' consequences is imperfect, captured by a non-systematic error as described in Section 2.7. The same holds for errors the headquarters is afflicted with when - depending on the mode of coordination - intervening in decision-making (see Section 2.8).
- As familiar in reinforcement learning, the options of task formation at hand are chosen according to their particular probabilities (rather capturing propensities); and these probabilities are updated according to the success or failure of the options in the past (reinforcement) (see Sections 2.6 to 2.27).
Observation: For model analysis, in each \(T^*\)-th period the task formation chosen was recorded. Additionally, the task formation in the final period (i.e., \(M_{t=500}\)) and the final performance (\(V_{t=500}\)) is observed[4]. From this, the final performance averaged per task formation and the relative frequency of the final task formation was calculated. Moreover, for each simulation run further metrics are recorded, like the number of changes in the task formation, the number of alterations in the configuration of the organization's decision problem and the ratio of false positive alterations in the observation period.
Details
Initialization
After a performance landscape is generated, the initial task formation and, hence, the number of units \(M_{t=0}\) is determined out of the set of options \(A\) at random with uniform probabilities, i.e., \(p(M^a,t=0)=\frac{1}{\vert{A}\vert}\). Then the organizations are "thrown" randomly in the performance landscape.
Input
After initialization, the environmental conditions, i.e., the complexity of the task and the "pattern" of interactions among the single choices of the decision problem \(\vec{d}_{t}\) as well as the contributions \(C_i\) to overall objective remain constant over time. Hence, there are no exogenously imposed dynamics after initialization; dynamics result merely endogenously from the adaptation and learning processes.
Submodels
With respect to the research question of the paper, in particular those submodels which are related to the coordination among decision-making agents' preferences and the reinforcement learning on task formation are described more into detail[5].
Coordination Mechanisms. The first forming of preferences by the units as described in Sections 2.14 and 2.15, in principle, follows the idea of a steepest ascent hill-climbing algorithm (Chang & Harrington 2006), though in a decentralized manner, i.e., performed by each of the units related to the respective partial decision problems. Afterwards, these once formed preferences may be coordinated among the \(M_t\) units, and the model comprises different ways of coordination (for these and other modes see Siggelkow & Rivkin 2005; Malone & Crowston 1994; Martial 1992):
The ”decentralized” mode , in fact, may be regarded as refraining from any coordination and, at large, corresponds to what Horling & Lesser (2004) categorize as "congregations" in terms of rather loosely collaborating agents: The units make their partial choices \(\vec{d}^{r}_{t}\) autonomously without "asking" other agents. Hence, each unit head is allowed to choose its most preferred option, denoted by \(\vec{d}^{r,p1}_{t}\), whichever it is out of the three options possible (status quo, \(a1\) and \(a2\)). The overall configuration \(\vec{d_t}\) simply results as an "assembly" from the units' first preferences on their partial decision problems.
The "sequential" mode captures what is named "sequential planning". The units make their choices sequentially where, for the sake of simplicity, the sequence is given by the index \(r\). In particular, unit \(r\) with \(2\leq r\leq{M}\) is informed by unit \(r-1\) about the choices made so far, i.e., made by the "preceding" units \(< r\). Unit \(r\) takes these choices into account and (potentially imperfectly) re-evaluates its own options \(\vec{d}^{r*}_{t-1}, \vec{d}^{r,a1}_t\) and \(\vec{d}^{r,a2}_t\) with respect to Equation 4 - potentially resulting in adjusted preferences. Hence, the eventually “new” first preference \(\vec{d}^{r,p1}_{t}\) for unit \(r\geq 2\) is a function of the choices of the “preceding” units and, obviously, only unit 1 does not have to take a previous choice into account:
| $$\vec{d}^{r*}_{t}= \left\{\begin{array}{rl} \vec{d}^{r,p1}_{t}\left(\vec{d}^{r-1,p1}_{t}\right) & \mathrm{for\hphantom{0}}2\leq{r}\leq{M_t}\\ \vec{d}^{r,p1}_t & \mathrm{for\hphantom{0}}r=1 \end{array}\right. \label{sequential}$$ | (5) |
In the “proposal” mode, each unit transfers its ordered list of preferences to the headquarter. The headquarter compiles the first preferences to a composite vector \(\vec{d}^C\) and assesses the overall performance it promises. However, like the units, the headquarter is not able to perfectly ex ante evaluate options (see Section 2.8). The headquarter's ex ante evaluation of option \(\vec{d}^ C\) follows from \(\tilde{V}(\vec{d}^ C)={V}(\vec{d}^ C)+{e}^{head}(\vec{d}^ C)\). The headquarter decides in favor of the composite vector \(\vec{d}^ C\) if it promises the same or a higher performance as the status quo \(\vec{d}_{t-1}\):
| $$\tilde{V}(\vec{d}^ C) \geq {V}(\vec{d}^*_{t-1}) \label{headcondition}$$ | (6) |
Reinforcement Learning. To induce emergence of task formation, the model employs a simple mode of reinforcement learning based on statistical learning (for overviews, see Sutton&Barto 2012; Kaelbling et al. 1996): a generalized form of the Bush & Mosteller (1955) model (Brenner 2006). The probabilities of alternatives \(M^a\) from a set \(A=\left\{M^1,...,M^{a},...,M^{\vert{A}\vert}\right\}\) (with \(1\leq a\leq \vert{A}\vert\)) of feasible task formations are updated according to the - positive or negative - stimuli resulting from the performance enhancement \(\Delta{V}_t\) achieved with the current configuration \(M_t \in A\). \(\Delta{V}_t\) is the relative enhancement of overall performance (see Equation 2) obtained in the last \(T^*\) periods, i.e.,
| $$\Delta{V}_t(M_t) = \frac{V_{t} - V_{t-T^*}}{V_{t-T^*}} $$ | (7) |
| $$ \tau(t)= \left\{\begin{array}{rl} 1 & \mathrm{if\hphantom{0}} \Delta{V}_t(M_t) \geq v_t \\ -1 & \mathrm{if\hphantom{0}} \Delta{V}_t(M_t) < v_t \end{array}\right.$$ | (8) |
Let \(p(M^a,t)\) denote the probability[7] of an alternative number of subtasks/units \(M^a\) to be chosen at time \(t\) for the next \(T^*\) periods. The probabilities of options \(M^{a} \in A\) are updated according to the following rule, where \(\lambda\) (with \(0 \leq \lambda \leq 1\)) reflects the reinforcement strength (Brenner 2006):
| $$p(M^a,t+1) = p(M^a,t) +\left\{\begin{array}{ll} \hphantom{-}\lambda\cdot\ (1-p(M^a,t)) & \mathrm{if\hphantom{0}} M^a=M_t \wedge\ \tau(t) = 1 \\ -\lambda\cdot\ p(M^a,t) & \mathrm{if\hphantom{0}} M^a=M_t \wedge\ \tau(t) = -1 \\ -\lambda\cdot\ p(M^a,t) & \mathrm{if\hphantom{0}} M^a \neq M_t \wedge\ \tau(t) = 1 \\ \hphantom{-}\lambda\cdot\ \frac{p(M^a,t)\cdot p(M_t,t)}{1-p(M_t,t)} & \mathrm{if\hphantom{0}} M^a \neq M_t \wedge\ \tau(t) = -1 \end{array}\right. \label{updateprobs}$$ | (9) |
Scenarios and Simulation Experiments
The very core of this study is to investigate which task formation emerges for different levels of task complexity. Therefore, the study differentiates between two types of interaction structures which, in a way, represent two basic types of interaction structures (for these and other structures see Rivkin & Siggelkow 2007).
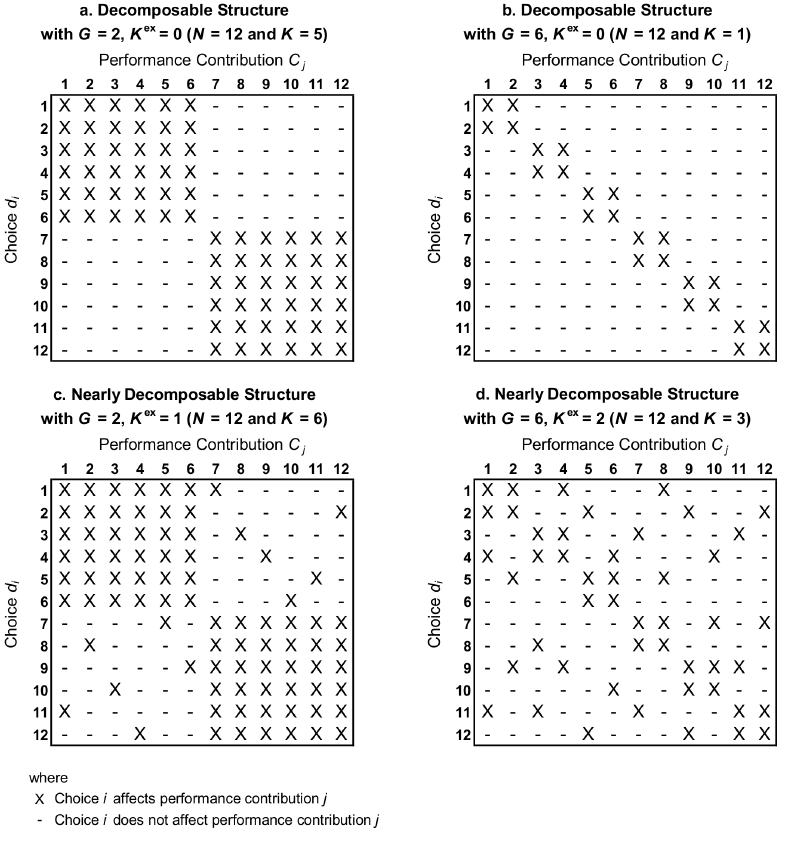
First, structures with purely “local” interactions are simulated, i.e., structures where choices within a “group” affect each others’ contributions to overall performance, while no interactions across the groups exist. Hence, these structures are perfectly decomposable (e.g., Rivkin & Siggelkow 2007; Simon 1962); for studies analyzing decomposable structures in the NK framework see, for example, (Rivkin & Siggelkow 2003; Siggelkow & Levinthal 2003). In the field of organizational design these structures have also been called “self-contained” (Galbraith 1974) and they capture situations where, for example, the task of an organization is perfectly decomposable along geographical regions or along products without any interdependencies across regions or products, respectively. Obviously, these structures show a limited coordination need across the blocks (Galbraith 1973; Malone & Crowston 1994). Examples of symmetric decomposable interaction matrices with two and six blocks (i.e., \(G=2\) and \(G=6\)) are depicted in Figures 2a and 2b, respectively. The simulation experiments are conducted for five different symmetric decomposable structures with a number of 2, 3, 4, 6 and - as a borderline case of \(K=0\) - 12 groups \(G\) of equal size where only local interactions occur.
The second type of interaction structures simulated shows near decomposability, i.e., interaction matrices with \(K^{ex}>0\) are studied, with \(K^{ex}\) denoting the level[8] of cross-group (or external) interactions of choices \(i\). In an organizational context, interactions among the modules \(G\) may be, for example, caused by certain contraints of resources (e.g., budget or capacities), by market-driven interactions (e.g., the price of one product may affect the price achievable for another product) or functional interrelations (e.g., the product design affecting the production processes) (Galbraith 1973). The more cross-group interactions exist (i.e., the higher \(K^{ex}\)), the more does the influence matrix approach the idea of reciprocal interdependencies as introduced by Thompson (1967) and the higher the coordination need among the choices (Malone & Crowston 1994). Figure 2.c depicts a situation with \(G=2\) and \(K^{ex}=1\); with \(N=12\), this situation results in \(K=6\) according to the NK framework[9]; a structure with \(G=6\) and \(K^{ex}=2\) (and, with this, \(K=3\)) is displayed in Figure 2.d.
Figure 3 summarizes the influence matrices for which simulation experiments are presented in this study. For every interaction structure in combination with each mode of coordination analyzed, 2,500 simulations are run, i.e., for each combination 10 runs on 250 distinct landscapes.
The interaction structure among the single decisions of an organization's overall decision problem reasonably shapes the need to coordinate the single choices with respect to the overall organizational objective (see Equation 2). While the interactions among decisions \(d_i\) in the model are regarded as being exogenously given (i.e., by the “nature” of the decision problem \(\vec{d}\)), the formation of tasks and, hence, the number of units employed is subject to learning-based emergence. However, the coordination mode employed (see 2.22 to 2.25) in the organization may interfere with the emergence of task formation. Hence, the simulation study comprises three types of simulation experiments:
- Decomposable interactions structures and coordination mode "decentralized'': These experiments capture the baseline scenarios where the nature of the overall decision problem would allow to find task formations without coordination need among the tasks. The interesting question is, whether these task formations emerge.
- Nearly decomposable interaction structures and coordination mode “decentralized”: These experiments allow to stepwise raise the coordination need due to the “real” nature of the decision problem. It is of particular interest to study in how far the task formations emerged for decomposable structures (see above) also emerge with increasing cross-group interactions.
- Decomposable and nearly decomposable interaction structures and coordination modes “sequential” and “proposal”: These experiments are conducted to study, in particular, in how far the emergence of task formation is affected by the mode of coordination employed by an organization.
The simulation experiments presented subsequently report on the results obtained for an observation time of \(T=500\) periods (see also Table 1). It is obvious, that the observation time could be of critical relevance when learning-based emergence is studied: In particular, choosing a too short observation time, clearly bears the risk that the learning processes do not have "enough" time to lead to some predominance of certain task formations. Obviously, this is of particular relevance with respect to the fact that in the simulations different levels of problem complexity are depicted: it is well known, that more time is required to find superior solutions for complex problems (Rivkin & Siggelkow 2007). Hence, in order to find an appropriate observation time, pre-tests for different levels of complexity were conducted. These tests indicated that even increasing the observation time remarkably does not change the key results. As shown exemplarily in Table 2 (Appendix B) doubling the observation time from \(T=500\) to \(T=1000\) does not only lead to the same task formations (given by \(M_t\)) emerging for the respective different levels of complexity, but also the final performances achieved do not differ significantly (even not when the requirements for significant differences are set to a rather low level).
Results and Discussion
Emergence of task formation in decomposable interaction structures and coordination mode "decentralized"
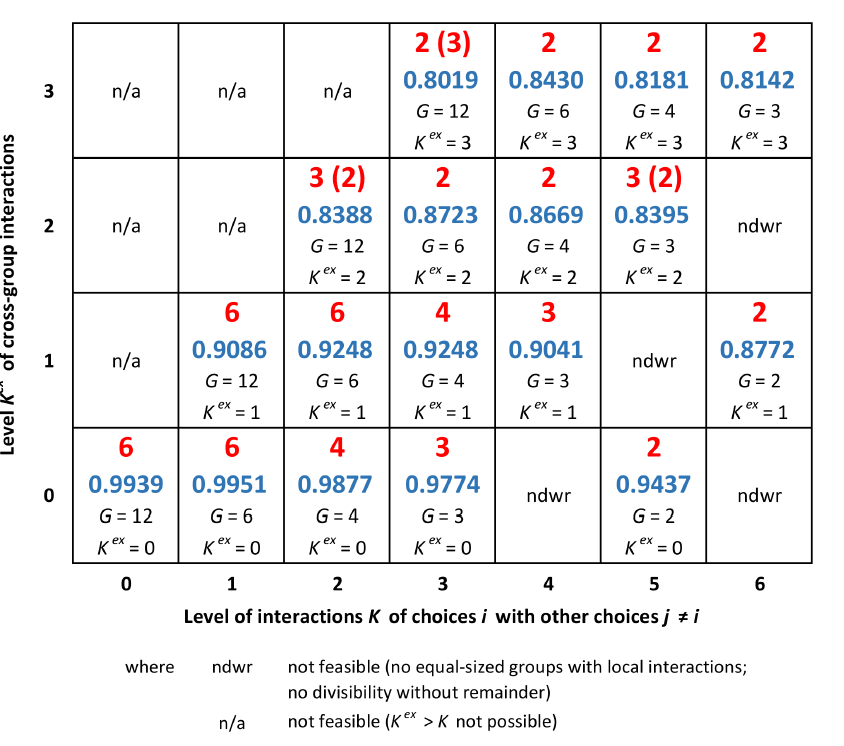
The results obtained for the different decomposable interaction structures under investigation and for situations where, in fact, no coordination is provided ("decentralized") are presented in Figures 4.a to 4.e: The simulation runs were grouped according to the number \(M_{t=500}\) of units out of set \(A\) (with \(\vert{A}\vert=4\), see Table 1) that were employed in the final observation period. For these four setups the average of the final performance is computed and displayed in the plots, i.e., that level of \(V_{t=500}\) which is on average achieved with a particular number \(M_{t=500}\) of units in the final period. (For each decomposable interaction structure, Table 3 in the Appendix reports on the significance of mean differences of final performance \(V_{t=500}\) between the four different setups of \(M_{t=500}\) according to Welch's method (Welch 1938; Law 2007). Moreover, the plots show the relative frequency of how often, in the final period, a certain task formation, and, thus, number of units \(M_{t=500}\) has been selected by the organization.
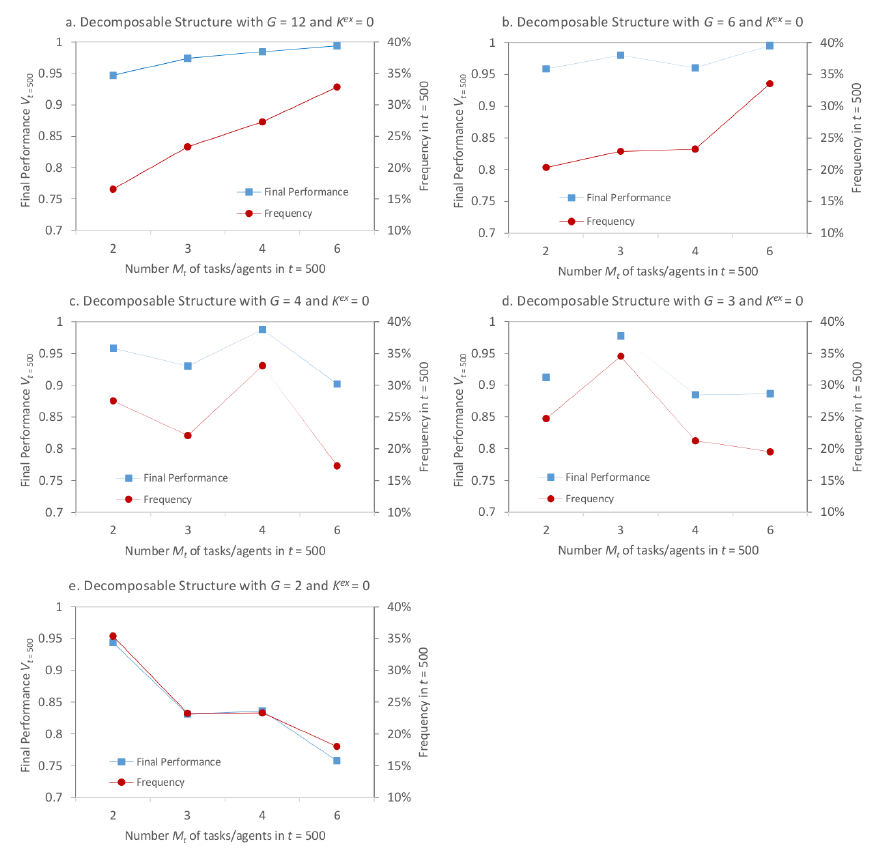
According to these results, that particular task formation \(M_{t=500}\) emerges most often which corresponds best to the number of groups \(G\) with local interactions incorporated in the interaction matrix: For example, for an interaction structure with \(G=3\) a segmentation in \(M_{t=500}=3\) sub-tasks emerges most often (see Figure 4.d) and the final performance is significantly the highest for that particular configuration (see Table 3 in Appendix B). The corresponding findings arise for the other decomposable interaction structures studied.
An explanation may, of course, lie in the fact that with the task formation (and the related number of units) the level of interactions across tasks/units is affected. For example, for an interaction structure of \(G=2\) and \(K^{ex}=0\) like in Figure 2.a, segmenting the \(N=12\)-dimensional task into 3 sub-tasks (and employing 3 units accordingly) would mean that some intra-group interactions are not taken into consideration by the decision-making units appropriately. Hence, the self-adaptive task formation apparently leads to setups where intra-group interactions are "residing" within the sub-tasks or, in other words, are in the scope of one unit.
However, results suggest that not only task formations with zero cross-task interactions emerge; rather, it appears that the highest feasible number of sub-tasks/units without causing cross-task interactions emerges: for example, for an interaction structure with \(G=6\) and \(K^{ex}=0\) (see Figure 4.b) even with \(M=2\) and \(M=3\) sub-tasks/units no cross-task interactions would show up; however, according to Figure 4.b, a setup with 6 tasks/units emerges most often and shows the highest final performance. The same applies to \(G=4\) and \(K^{ex}=0\) where, according to Figure 4.c, not setups with 2, but with 4 sub-tasks/units emerge most often and (significantly) show highest final performance).
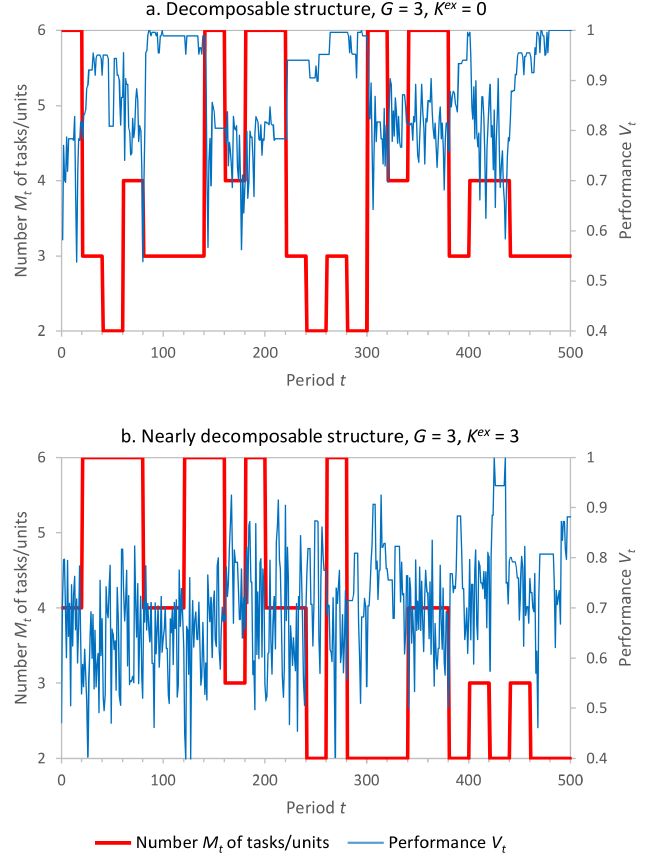
For an illustration more into detail, Figure 5.a plots a “typical” single adaptive walk for an interaction structure with \(G=3\) and \(K^{ex}=0\). It becomes obvious that, whenever the number of tasks (units) deviates from \(M_t=3\) - here reflecting isomorphism - performance losses occur. Performance losses are particularly high when the number of tasks (units) is higher than \(G\). In contrast, when the isomorphic task formation with \(M_t=3\) is implemented, performance rapidly increases to a rather high level.
Hence, according to these results, setups which maximize the number of tasks/units without causing cross-task interactions emerge most often and result in the highest final performance. This finding, obviously, is in line with the idea of isomorphism in terms of mirroring the "real" structure of the task in the task formation in organizations (e.g., (Wood 1986; Baldwin & Clark 2000; Ethiraj & Levinthal 2004) as well as the “functionally accurate/cooperative (FA/C)” model for distributed problem solving (Lesser 1991).
The capacity for search which is affected by the number of decision-making units reasonably provides the explanation for these results: In the model, it is assumed that the capacity for search per decision-making unit is limited regardless of its scope of competence in order to capture the limited human information-processing capabilities (Simon 1955): In particular, in time step, each unit discovers two alternatives \(a1\) and \(a2\) where one or two bits, respectively, are flipped compared with the status quo. Hence, for \(N=12\) and with 6 units, in principle, in one time step the entire configuration \(\vec{d_t}\) could be altered, whereas with two units at maximum 4 of 12 \(d_i\) can be modified. Thus, with the number of units the capacity of search is increased and, thereby, potentially performance enhancements can be achieved faster with more units (see also, for example, Baldwin & Clark 2000; Ethiraj & Levinthal 2004).
Hence, a trade-off between the capacity of search and the scope of competence reasonably occurs which - for decomposable interaction structures - apparently results in a task formation with as many as possible sub-tasks/units without causing interactions between tasks/units.
Emergence of task formation in nearly decomposable interaction structures with coordination mode "decentralized"
The next step of this simulation study is to investigate the emerging task formations for nearly decomposable tasks, i.e., for situations where no segmentation into sub-tasks without causing cross-task interactions is feasible (i.e., \(K^{ex}>0\)). In particular, this section introduces the results obtained from simulation experiments for the structures indicated in Figure 3 for levels of \(K^{ex} \in \left\{1,2,3\right\}\) and for "decentralized" coordination.
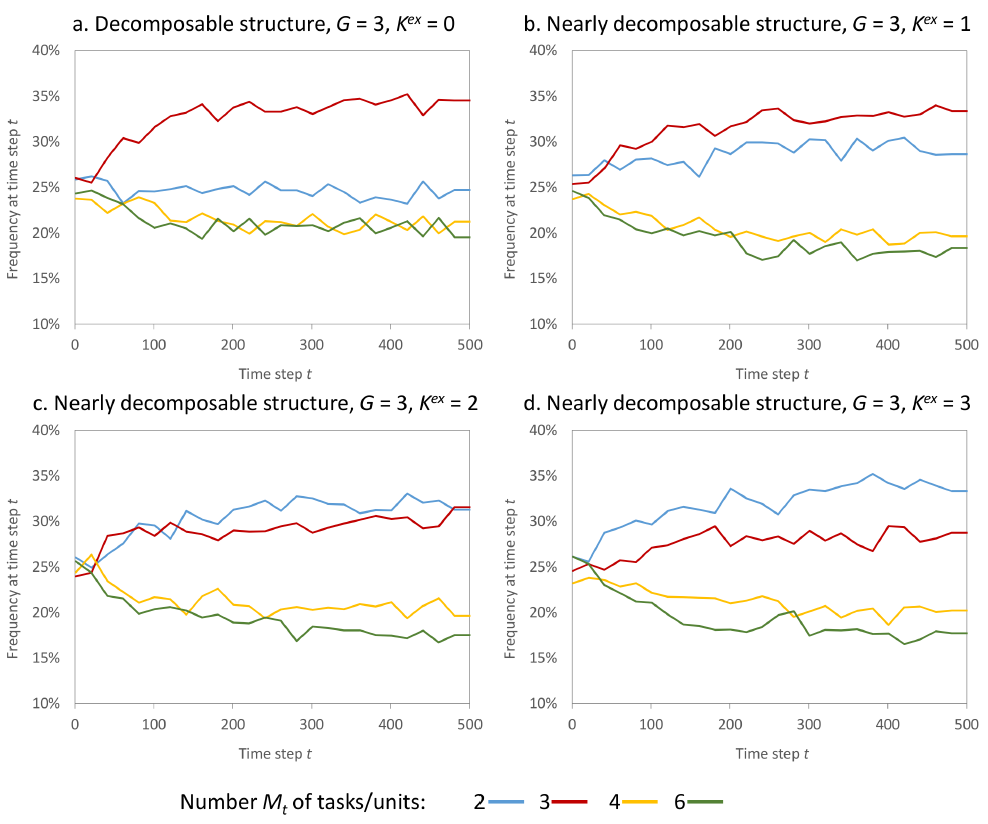
For these experiments the same analyses as introduced in the preceding section are carried out. However, now a more condensed presentation is appropriate. In particular, Figure 6 picks up the presentation of Figure 3 and in each cell – apart from the characterization of the interaction structure by \(G\) and \(K^{ex}\) - the number \(M_{t=500}\) of sub-tasks/units which emerges most often (large bold letters in red) and with the highest final performance \(V_{t=500}\) (numbers in blue) is given. When significance at a 0.99 level of the best performing task formation according to the method of Welch (1938), (Law 2007) is not reached, then the task formation with the second-highest final performance is displayed in brackets. Figure 7 exemplary plots the relative frequencies of the different feasible numbers of sub-tasks/units \(M_t\in A\) over the observation time for an interaction structures with \(G=3\) and different levels of cross-group interactions \(K^{ex} \in \left\{0,1,2,3\right\}\).
The results indicate, that increasing the level of cross-group interactions from \(K^{ex}=0\) to \(K^{ex}=1\) apparently does not affect the predominantly emerging task formation as given by the number \(M_{t=500}\) of sub-tasks or units employed in the organization. However, as can be seen from comparing Figure 7.a to 7.b, the predominance of \(M_{t=500}=3\) over \(M_{t=500}=2\) decreases when \(K^{ex}\) is raised to 1.
With \(K^{ex}\geq 2\), things change: the results indicate that then the number of sub-tasks and units \(M_{t=500}\), respectively, employed in the organization is reduced to a considerably lower level. Obviously, with segmenting the overall task into two sub-tasks only, the scope of competence of the decision-making units is raised to a maximum and cross-group interactions are at the best comprised within the scope of the units' competences. However, this comes at the cost of search capacity (recall that with two units at maximum 4 of the \(N=12\) choices \(i\) of the search problem can be altered in one time step).
To illustrate these effects more into detail, Figure 5.b displays a "typical" adaptive walk for \(G=3\) and \(K^{ex}=3\): Compared to the case of no cross-group interactions (\(K^{ex}=0\)) in Figure 5.a , obviously, the oscillations of performance are much stronger. This is caused by the fact, that now the choices of one unit may considerably affect the performance obtained by the choices of other units and, thus, are inducing the other units to alter the solutions to their respective partial problems. In this interaction structure, a formation with only two tasks (units) apparently provides the best results and, whenever this task formation is implemented, performance increases and fluctuations decrease - though remaining at a notably high level compared to the decomposable structure.
Hence, the results indicate that with increasing complexity of the search problem the balance between search capacity and scope of competence shifts towards broader competence and lower search capacity (and vice versa).
Reducing cross-task interactions between sub-tasks by shaping rather broad, but few sub-tasks, obviously, has the advantage that the related decision-making units consider more spillover effects among the \(N\) single decisions when making their choices on their partial decision-problem. However, it worth mentioning, that - at a given level of \(N\) - broader, though fewer sub-tasks may have another positive effect which is related to imperfect sensing of decision makers incorporated in the model:
Among the informational imperfections captured in the model is that - when first forming their preferences - the decision-making units assume that the other units' managers will stay with their prior choice (see Section 2.16). Hence, the broader the "own" scope of competence (i.e, the higher \(N^*=N/M_t\)) the lower is the potential "error" that each of the \(M_t\) decision-making units makes regarding the anticipation of the other units' choices: From each unit manager's perspective, the number of those particular choices which are assumed to remain unchanged is given by \(N-N^*\). In other words, when forming preferences each decision-maker assumes a ratio \(s_t = 1-\frac{1}{M_t}\) of the \(N\)-dimensional decision-problem to be kept stable[10]. Hence, the less sub-tasks \(M_t\) are formed, the lower is the potential "error" made due to assuming that the fellow units will stay with their prior choices. However, the peril of misjudgements is subject to cross-task interactions: In case that the other units' choices affect the performance achieved by unit \(r\), it becomes more likely that a particular unit runs into danger of choosing an option that turns out particularly less beneficial than expected. Hence, with increasing \(K\) and \(K^{ex}\) the relevance of imperfect expectations regarding the fellow units' behavior becomes more relevant. From this, the obvious question arises, whether with more intense coordination mechanisms - which also incorporate more communication among units - the emerging task formations may differ which is analyzed in the next section.
Emergence of task formation with coordination modes "sequential" and "proposal"
The third part of the simulation experiments studies the task formation emerging under the regime of the "sequential" and the "proposal" coordination mode, respectively. Both mechanisms comprise the communication of units' preferences to another decision-making agent (another unit or the headquarter, respectively) and a second evaluation of options (based on more information than available in the formation of preferences). Figures 8 and 9 report on the condensed results regarding the emerging task formations in the format introduced in the preceding section.
In a rather broad sense, for both coordination mechanisms the results are in line with those obtained for the “decentralized” mode, i.e., in fact, without coordination: For decomposable interaction structures (i.e., for \(K^{ex}=0\)), those task formations emerge most often and show highest final performance which reflect the “real” nature of the overall task of the organization. Like in the "decentralized" mode, these task formations also emerge when the level of cross-group interactions \(K^{ex}\) is increased from 0 to 1, while, with \(K^{ex}\geq 2\), the emerging task formations differ, i.e., showing lower levels of \(M_t\).
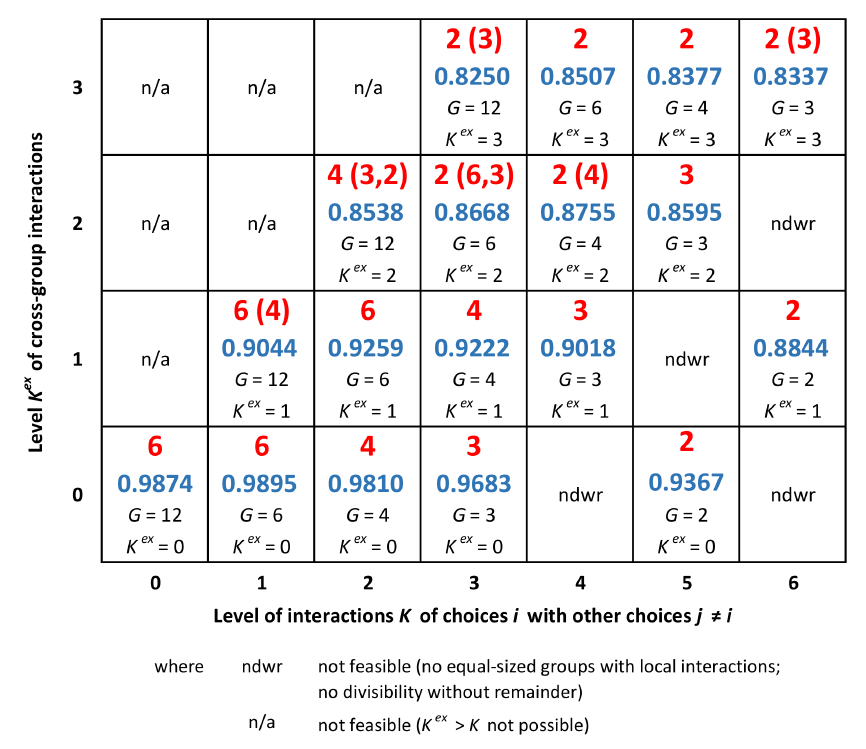
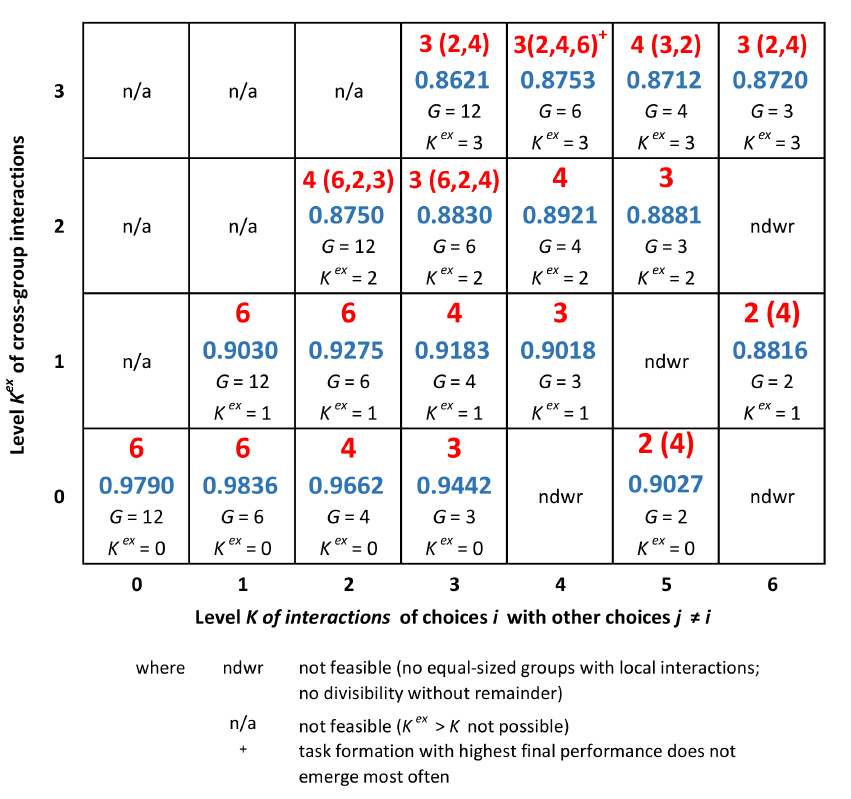
However, some aspects deserve closer attention: First of all, comparing the three coordination modes with respect to the emerging number \(M_{t=500}\) of sub-tasks/units, it is worth mentioning that, with the “sequential” as well as the “proposal” mode, for \(K^{ex}\geq 2\) the emerging task formations are less predominant in terms of significance than in the decentralized mode (in Figure 8 and 9 indicated by formations in brackets which have no significantly lower final performances).
A second aspect to be mentioned is related to the number \(M_{t=500}\) of tasks/units: In the "proposal" mode - where hierarchy comes into play - the task formations emerging for \(K^{ex}\geq 2\) show a remarkably higher segmentation than obtained in the other coordination modes. Apparently, the headquarter's evaluation of options with respect to the overall organizations objective serves as a kind of substitute for incorporating cross-group interactions within sub-tasks. This finding obviously is in line with organizational theory emphasizing the tension between differentiation and integration (Lawrence & Lorsch 1967; for further references, Wall 2016)[11].
Third, comparing the three coordination mechanisms with respect to the final performance \(V_{t=500}\) against each other suggests that for the case of perfectly decomposable problem structures (i.e., \(K^{ex}=0\)) the "decentralized" mode leads to the highest performance while the "proposal" mode results in the lowest performance (the performance differences are significant at a 0.99 level, see Table 4 in Appendix B). In contrast, with \(K^{ex}\geq 2\) the "order" among coordination modes is the opposite: apparently, for a given level of \(K\) the emerging task formations result in the highest performances under the "proposal" mode, the "sequential" mode yields the second-highest performances and the "decentralized" mode performs worst (in the vast majority of cases performance differences are significant, see Table 4 in Appendix B). With \(K^{ex}=1\), the three coordination modes provide final performances which do not differ significantly from each other.
Hence, an interesting question is what may cause these results. I argue that the coordination mode subtly interferes with the balance between capacity of problem-solving and scope of competencies - both shaped by the number of units \(M_t\): As already mentioned, with the number of units \(M_t\) the capacity of problem-solving increases and, in the model, each decision-making unit, at maximum, may change two of the single decisions \(d_i\) delegated to that unit. With this, the ratio of decisions (bits) \(d_{it}\) in the \(N\)-dimensional decision problem that might be changed in each time step increases in \(M\) and is given by \({\frac{2}{N}}\cdot M\). When forming preferences, in the "decentralized" mode, unit \(r\) assumes that all the fellow units stay with the status quo, and, with this, unit \(r\), at maximum, may be wrong by a ratio \({\frac{2}{N}}\cdot (M-1)\) of the overall decision problem. In the "sequential`'' mode, the error due to imperfect anticipation of the fellow units' intentions in average is only half as high and is given by \({\frac{1}{N}}\cdot (M-1)\) (recall that here, when making the decision, unit \(r\) knows which choices the units 1 to \(r-1\) have opted for) [12].
Hence, the "sequential" mode allows for increasing the problem-solving capacities as given by \(M\) while the error made by the imperfect anticipation of the other units' intentions in average increases only half as much as in the "decentralized" mode. This explanation is broadly confirmed by the number of periods with false positive choices: For example, for \(K^{ex}=2\), this ratio is about 6 points of percentage lower with the "sequential" mode than with the "decentralized" mode of coordination. However, the (imperfect) anticipation of the other units' intentions, obviously, is the more relevant the higher the level of interactions \(K\) and cross-group interactions \(K^{ex}\). This may, in particular, explain the differences in the number of units and the final performances between the decentralized and the sequential mode for higher levels of \(K^{ex}\).
In the “proposal” mode, the balance between sub-systems' capacity of problem-solving and sub-systems' scope of competencies is shifted towards the former even more than with sequential planning, and I argue that this results from a switch in the objective function relevant for the final choices combined with the headquarter's knowledge of all units' preferences:
In particular, in the proposal mode the headquarter performs a second evaluation of the options favored by the units, and, this - though based on the headquarter's rather coarse knowledge (in the model captured by a fairly high level of noise) - with respect to the overall objective. In contrast, in the other coordination modes the evaluations and final choices are based on the subunits' objective functions[13], and, obviously, this kind of "ignorance" is the more relevant, the higher the levels of \(K\) and \(K^{ex}\).
These arguments are broadly supported by the ratio of periods with false positive choices: for example, for \(K^{ex}=2\), in the "proposal" mode false positive alterations of \(\vec{d_t}\) occur in approximately 15 percent of the periods while occurring in about 29 percent of periods in the "sequential" mode. Moreover, this explanation is in line with the argumentation put forward in the seminal paper of Sah & Stiglitz (1986) which shows that false positive choices are considerably reduced by employing hierarchical structures in decision-making. Hence, even for decision-problems with higher complexity, apparently integration via hierarchy - as captured in the proposal mode - allows to make use of a higher problem-solving capacity due to high levels of differentiation.
Conclusion
This study analyses the emergence of task formation under conditions of limited knowledge about the "real" structure of the problem to be solved by an organization and when further limitations regarding the information-processing capabilities of decision-making agents apply.
The results indicate that, under these conditions and for decomposable problems, task formations emerge which follow the idea of isomorphism, i.e., task formations mirroring the fragments of the overall problem which is, for example, recommended in the field of design of complex systems as well as proposed in organizational theory (Baldwin & Clark 2000; Ethiraj & Levinthal 2004; Galbraith 1973). The results suggest that the emergence of “isomorphic” task formations is rather robust against the mode of coordination – may this be of a polyarchic or a hierarchical nature (Sah & Stiglitz 1986). Moreover, this emergence of task formations appears to be rather "robust" against a low level of interactions across the fragments of the "real" problem of an organization: With only some few interactions the same task formations emerge as for perfectly decomposable structures, regardless of the mode of coordination employed.
With higher levels of interactions among segments, a clear shift towards task formations with lower number of agents or broader scopes of agents' competencies, and, with that, lower capacity of problem-solving results. Obviously, thereby interactions among segments of the "real" problem are incorporated into the tasks. This tendency shows up for all coordination modes under investigation. However, with hierarchical coordination - which provides the most intense integration among tasks under investigation - higher levels of segmentation (i.e., smaller, but more tasks) emerge, and, with this, more parallelized problem-solving capacity is affordable. Hence, more intense coordination serves as substitute for the low segmentation which is in line with the well-known tension between differentiation and integration in organizational theory (Lawrence & Lorsch 1967).
In sum, the results suggest that with increasing task complexity the balance between problem-solving capacity and competence shifts in favor of broader competence and lower capacity (and vice versa). However, the coordination mode appears to affects this balance too: with more intense coordination, more segmentation providing more parallel problem-solving is affordable.
It is worth mentioning, that these findings are derived from a model with agents (i.e., only locally optimizing units as well as the headquarter) which follow very simple - for not to say mechanistic - decision and learning rules and which have limited information on the entire solution space and a rather limited memory. Hence, on the one hand one may argue that these assumptions could be too restrictive in respect of, for example, the spectrum of capabilities of organizations. On the other hand, the fact that the shown emergence results from rather simple rules, local optimization and limited information may put top-down approaches in management into some perspective. At the same time, the findings of this study indicate that the nature of an organization's overall task as well as the regime in terms of the intensity of coordination shape the emerging task formation. In this sense, this study may contribute to the field of organizational design in several aspects.
From a more practical point of view, the results are particular relevant for situations when the organizational structure is designed without being perfectly informed about the nature of the overall problem to be solved. For example, the organization may be newly established or the organization's task environment may have gone through an external shock, e.g., due to disruptive technological innovations. In this respect, the results may be regarded as an affirmation to allow for learning-based adaptation of the organizational structure.
From a more theoretical perspective, the findings, for example, let us conjecture that firms in complex task environments may show a relatively lower number of business units or are making use of more intense coordination modes; firms which are diversified according to products or regions are expected to reflect this in their formation of units. In this sense, the study may be of interest for further empirical research on the relation of organizational complexity and governance structure as, for example, in Bushman et al. (2004), Anderson et al. (2000) or Bushman et al. (1995). While the research questions of the study introduced here aims on findings related to this more organizational level, as an agent-based simulation, it builds on behaviors and interactions related to the individual level of decision-makers like, for example, imperfect ex ante-assessments of options or the coordinative behavior. However, apart from the simple decision rules captured in this paper's model, for example, the agents' behavior in the course of coordination is not affected by the task complexity (Liu & Li 2012). It could be of particular interest to connect the modelling of this study with laboratory experimental research on task complexity and coordination (e.g., (Ho & Weigelt 1996) in order to test and refine the model.
Further extensions of this study appear promising and, in particular, it is to be mentioned that the results are obtained for binary decision problems as captured in the NK framework. This has obvious advantages with respect to controlling the level of task complexity; however, apart from the structure of interactions, it provides a rather low structure with respect to the (randomized) contributions to performance; hence, in further research studies learning-based adaptation of task formation may turn out even more beneficial in case of more structured problems. Moreover, the simulation experiments introduced here do not consider costs of coordination: more intense coordination usually does not come along without costs (e.g., for communication). Hence, an obvious extension is to analyze self-adaptive task formations for different modes of coordination including its costs too. With respect to the form of learning employed to induce emergence, it would be interesting to investigate whether other models of learning like, for example, belief learning or melioration learning (Brenner 2006; Zschache 2017) lead to similar results.
Moreover, in the research effort presented here, the decision-making agents - though having distinct tasks and different information - are homogenous in several aspects as, for example, with respect to their information-processing capabilities. Hence, a natural extension would be to investigate systems with more heterogeneous agents (for example, with respect to learning and problem-solving capabilities). Hence, this would also imply to consider aspects of task allocation in terms of answering the question of which task should be assigned to which particular agent. This question of task allocation which was excluded from the study presented here could lead to further insights bridging to the domain of human resource management.
Acknowledgements
A prior version of this paper was presented at the PRIMA 2017: 20th International Conference on Principles and Practice of Multi-Agent Systems, Nice, 30th October – 3rd November 2017. The author gratefully acknowledges the valuable comments of the conference’s participants as well as the helpful suggestions of the reviewers of JASSS.Notes
- With \(N=12\), an interaction matrix has 144 entries, of which those on the main diagonal are always set to "X" (see Figure 2). Hence, 132 other elements remain, each of which could be filled or not, and - since the level of \(K\) does not necessarily need to be the same for every single decision \(i\) - with \(N=12\) in sum \(2^{132}=5.44452\cdot10^{39}\) different interaction structures are possible. For a further discussion of different interaction structures see (Rivkin & Siggelkow 2007)
- Obviously, with \(N \in \mathbb{N}\) this requires that \(N\) is divisible by \(M_t\) without remainder. With \(N=12\) and if, for example, a number of \(M_t=3\) subtasks has emerged at time step \(t\), then each subtask comprises \(N^*=4\) single choices.
- With this, the \(N\)-dimensional decision problem \(\vec{d_{t}}=(d_{1t},...d_{Nt})\) can also be expressed by the combination of partial decision problems as \(\vec{d_{t}}=\left[\vec{d}^1_{t}...\vec{d}^r_{t}...\vec{d}^{M_t}\right]\) with each unit's choices related only to its own partial decision problem \(\vec{d}^r_{t}\).
- The final performance \(V_{t=500}\) is given in relation to the global maximum of the respective performance landscape: otherwise the results could not be compared across different performance landscapes.
- More “technical” documentations on the framework of NK fitness landscapes including aspects of implementation can be found in Altenberg (1997) and Li et al. (2006).
- The aspiration level \(v_t\) is modified according to the performance experience and, in particular, is captured as an exponentially weighted moving average of past performance where \(b\) denotes the speed of adjustment (Böergers & Sarin 2000; Levinthal 2016), i.e., \(v_t = b\cdot \Delta{V}_{t-T^*} +(1-b)v_{t-T^*}\).
- For the probabilities \(p(M^a,t)\) it holds that \(0\leq p(M^a,t) \leq 1\) and \(\sum_{M^a\in A} (p(M^{a},t))\)\(=1\).
- In the simulations, for the sake of simplicity, the level of \(K^{ex}\) is assumed to be the same for each contribution \(C_i\), \(i=(1,...,N)\).
- Recall that, according to the NK framework, \(K\) captures the number of choices \(j \neq i\) which affect the contribution \(C_i\) of choice \(i\) to overall performance \(V\).
- With each unit's scope of competence at time step \(t\) being \(N^*=N/M_t\) and the "residual" part of the decision problem in the competence of other unit managers being \(N-N^*\), the relative size \(s_t\) of the residual part from each unit's perspective results from \(s_t=(N-\frac{N}{M_t})\cdot\frac{1}{N}= (1-\frac{1}{M_t})\).
- For example, in their seminal paper Lawrence & Lorsch (1967) state that “differentiation and integration are essentially antagonistic, and that one can be obtained only at the expense of the other” (p. 47).
- In particular, unit \(r\) knows the choices of the "prior" units in the sequence but assumes that the "subsequent" units will stay with the status quo. With this, unit \(r\), at maximum, is wrong by a ratio of \({\frac{2}{N}}\cdot (M-r)\) and, the average unit's maximum ratio of error is \({\frac{1}{N}}\cdot (M-1)\).
- In particular, without further institutional arrangements like appropriate incentive schemes related to firm performance (Wall 2017), each subunit focuses on the “own” performance (see Equations 3 and 4) and not on the overall performance (see Equation 2).
Appendix
Appendix A: Flow chart
Appendix B: Tests of significance
Tables 2 to 4 report results obtained from comparisons of means in terms of differences between means and the significances of these differences. For this, the Welch’s method (Welch 1938) as it is suggested for the analysis of simulation experiments is employed (Law 2007).
| Interaction Structure | Number of Mt=500 Tasks/Units predominantly emerging for | Mean differences and confidence intervals | |
| Mt=500 | Mt=1000 | ||
| G = 3; Kex = 0 | 3 | 3 | -0.0005± 0.0021n |
| G = 3; Kex = 1 | 3 | 3 | 0.0044± 0.0065n; |
| G = 3; Kex = 2 | 3 | 3 | 0.0006±0.0091n |
| (2) | (2) | (-0.0022 ±0.0085n) | |
| G = 3; Kex = 3 | 3 | 3 | -0.0009 ±0.0088n |
| Interaction Structure | Mt=500 | Number of Tasks/Agents | ||
| 3 | 4 | 6 | ||
| G = 12, Kex = 0 | 2 | 0.0272 ±0.0057* | 0.0376±0.0054* | 0.047±0.0051* |
| 3 | 0.0104±0.0032* | 0.0197±0.0028* | ||
| 4 | 0.0094±0.0019* | |||
| G = 6, Kex = 0 | 2 | 0.0212±0.0053* | 0.0014±0.0065 | 0.0364±0.0047* |
| 3 | -0.0197±0.0052* | 0.0152±0.0026* | ||
| 4 | 0.0349±0.0046* | |||
| G = 4, Kex = 0 | 2 | -0.0283±0.0081* | 0.0295±0.0042* | -0.0564±0.0111* |
| 3 | 0.0577±0.0072* | -0.0281±0.0125* | ||
| 4 | -0.0859±0.0105* | |||
| G = 3, Kex = 0 | 2 | 0.0653±0.0075* | -0.0275±0.0125* | -0.0258±0.0132* |
| 3 | -0.0928±0.0105* | -0.091±0.0114* | ||
| 4 | 0.0018±0.0151 | |||
| G = 2, Kex = 0 | 2 | -0.1126±0.0122* | -0.1074±0.0132* | -0.1857±0.0163* |
| 3 | 0.0052±0.017 | -0.0732±0.0195* | ||
| 4 | -0.0783±0.0202* | |||
| Level of Cross-group Interactions | Level of Interactions | Comparison of Coordination Modes | ||
| sequential vs. decentralized | proposal vs. decentralized | proposal vs. sequential | ||
| Kex = 0 | G = 12; K = 0 | -0.0065±0.0016* | -0.015±0.0035* | -0.0085±0.0037* |
| G = 6; K = 1 | -0.0056±0.0014* | -0.0115±0.0031* | -0.0059±0.0033* | |
| G = 4; K = 2 | -0.0067±0.0026* | -0.0215±0.0045* | -0.0148±0.0048* | |
| G = 3; K = 3 | -0.0091±0.0038* | -0.0332±0.0062* | -0.0241±0.0065* | |
| G = 2; K = 5 | -0.007±0.006* | -0.0411±0.0085* | -0.0341±0.0087* | |
| Kex = 1 | G = 12; K = 1 | -0.0042±0.0107 | -0.0056±0.0107 | -0.0014±0.0102 |
| G = 6; K = 2 | 0.0011±0.0091 | 0.0027±0.0095 | 0.0016±0.0086 | |
| G = 4; K = 3 | -0.0027±0.0095 | -0.0065±0.01 | -0.0038±0.0093 | |
| G = 3; K = 4 | -0.0023±0.0097 | -0.0023±0.0109 | -0.0001±0.0103 | |
| G = 2; K = 6 | 0.0071±0.0098 | 0.0044±0.0113 | -0.0028±0.0111 | |
| Kex = 2 | G = 12; K = 2 | 0.0149±0.0134* | 0.0361±0.0127* | 0.0212±0.0129* |
| G = 6; K = 3 | -0.0055±0.0118 | 0.0107±0.0116 | 0.0162±0.0116* | |
| G = 4; K = 4 | 0.0085±0.0113 | 0.0251±0.012* | 0.0166±0.0116* | |
| G = 3; K = 5 | 0.02±0.0134* | 0.0486±0.013* | 0.0286±0.0122* | |
| Kex = 3 | G = 12; K = 3 | 0.0231±0.0128* | 0.0602±0.0125* | 0.0371±0.0127* |
| G = 6; K = 4 | 0.0078±0.0124 | 0.0324±0.0132* | 0.0246±0.0131* | |
| G = 4; K = 5 | 0.0196±0.0131* | 0.0531±0.0134* | 0.0335±0.013* | |
| G = 3; K = 6 | 0.0195±0.0135* | 0.0578±0.0134* | 0.0383±0.0129* | |
References
ALTENBERG, L. (1997). 'Section B2.7.2: NK fitness landscapes.' in T. Back, D. Fogel & Z. Michalewicz (Eds.), ThecHandbook of Evolutionary Computation. Oxford: Oxford University Press, pp. B2.7:5–B2.7:10. http://dynamics.org/Altenberg/FILES/LeeNKFL.pdf.
ANDERSON, P. (1999). Complexity theory and organization science. Organization Science, 10(3), 216–232.
ANDERSON, R. C., Bates, T. W., Bizjak, J. M. & Lemmon, M. L. (2000). Corporate governance and firm diversification. Financial Management, 29(1), 5–22. [doi:10.2307/3666358 ]
BALDWIN, C. Y. & Clark, K. B. (2000). Design Rules: The Power of Modularity. Cambridge, MA: The MIT Press.
BÖERGERS, T. & Sarin, R. (2000). Naive reinforcement learning with endogenous aspirations. International Economic Review, 41(4), 921–950. [doi:10.1111/1468-2354.00090 ]
BRENNER, T. (2006). 'Agent learning representation: Advice on modelling economic learning.' In L. Tesfatsion and K.L. Judd (Eds.), Handbook of Computational Economics. Volume 2, North-Holland, NL: Elsevier, pp. 895-947.
BUSH, R. R. & Mosteller, F. (1955). Stochastic Models for Learning. Oxford: John Wiley & Sons. [doi:10.1037/14496-000 ]
BUSHMAN, R., Chen, Q., Engel, E. & Smith, A. (2004). Financial accounting information, organizational complexity and corporate governance systems. Journal of Accounting and Economics, 37(2), 167–201.
BUSHMAN, R. M., Indjejikian, R. J. & Smith, A. (1995). Aggregate performance measures in business unit manager compensation: The role of intrafirm interdependencies. Journal of Accounting Research, 33(Supplement), 101–129. [doi:10.2307/2491377 ]
CARLEY, K. M. & Zhiang, L. (1997). A theoretical study of organizational performance under information distortion. Management Science, 43, 976–997.
CARROLL, T. & Burton, R. M. (2000). Organizations and complexity: Searching for the edge of chaos. Computational and Mathematical Organization Theory, 6(4), 319–337. [doi:10.1023/A:1009633728444 ]
CHANG, M.-H. & Harrington, J. E. (2006). Agent-based models of organizations, vol. 2, book section 26, (pp. 1273– 1337). Amsterdam: Elsevier.
COLOMBO, M. G. & Delmastro, M. (2004). Delegation of authority in business organizations: An empirical test. The Journal of Industrial Economics, 52(1), 53–80. [doi:10.1111/j.0022-1821.2004.00216.x ]
ETHIRAJ, S. K. & Levinthal, D. (2004). Modularity and innovation in complex systems. Management Science, 50(2), 159–173.
GALBRAITH, J. R. (1973). Designing Complex Organizations. Reading (MA): Addison-Wesley.
GALBRAITH, J. R. (1974). Organization design: An information processing view. Interfaces, 4(3), 28–36.
GRIMM, V., Berger, U., Bastiansen, F., Eliassen, S., Ginot, V., Giske, J., Goss-Custard, J., Grand, T., Heinz, S. K., Huse, G., Huth, A., Jepsen, J. U., JÃÿrgensen, C., Mooij, W. M., Müller, B., PeâĂŹer, G., Piou, C., Railsback, S. F., Robbins, A. M., Robbins, M. M., Rossmanith, E., RÃijger, N., Strand, E., Souissi, S., Stillman, R. A., Vabo, R., Visser, U. & DeAngelis, D. L. (2006). A standard protocol for describing individual-based and agent-based models. Ecological Modelling, 198(1), 115–126. [doi:10.1016/j.ecolmodel.2006.04.023 ]
GRIMM, V., Revilla, E., Berger, U., Jeltsch, F., Mooij, W. M., Railsback, S. F., Thulke, H.-H., Weiner, J., Wiegand, T. & DeAngelis, D. L. (2005). Pattern-oriented modeling of agent-based complex systems: lessons from ecology. Science, 310(5750), 987–991.
GROSS, T. & Blasius, B. (2008). Adaptive coevolutionary networks: a review. Journal of the Royal Society Interface, 5(20), 259–271. [doi:10.1098/rsif.2007.1229 ]
HÆREM, T., Pentland, B. T. & Miller, K. D. (2015). Task complexity: Extending a core concept. Academy of Management Review, 40(3), 446–460.
HENDERSON, R. M. & Clark, K. B. (1990). Architectural innovation: The reconfiguration of existing product technologies and the failure of established firms. Administrative Science Quarterly, 35(1), 9–30. [doi:10.2307/2393549 ]
HO, T.-H. & Weigelt, K. (1996). Task complexity, equilibrium selection, and learning: An experimental study. Management Science, 42(5), 659–679.
HORLING, B. & Lesser, V. (2004). A survey of multi-agent organizational paradigms. Knowledge Engineering Review, 19(4), 281–316. [doi:10.1017/S0269888905000317 ]
KAELBLING, L. P., Littman, M. L. & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
KAUFFMAN, S. A. (1993). The Origins of Order: Self-Organization and Selection in Evolution. Oxford: Oxford University Press.
KAUFFMAN, S. A. & Levin, S. (1987). Towards a general theory of adaptive walks on rugged landscapes. Journal of Theoretical Biology, 128(1), 11–45.
LAW, A. M. (2007). Simulation Modeling and Analysis. New York: McGraw-Hill, 4 edn.
LAWRENCE, P. R. & Lorsch, J. W. (1967). Differentiation and integration in complex organizations. Administrative Science Quarterly, 12(1), 1–47.
LESSER, V., & Corkill, D. (2014, May). Challenges for multi-agent coordination theory based on empirical observations. In Proceedings of the 2014 international conference on Autonomous agents and multi-agent systems (pp. 1157-1160). International Foundation for Autonomous Agents and Multiagent Systems.
LESSER, V. R. (1991). A retrospective view of FA/C distributed problem solving. IEEE Transactions on Systems, Man, and Cybernetics, 21(6), 1347–1362.
LESSER, V. R. (1998). Reflections on the nature of multi-agent coordination and its implications for an agent architecture. Autonomous Agents and Multi-Agent Systems, 1(1), 89–111. [doi:10.1023/A:1010046623013 ]
LEVINTHAL, D. A. (2016). 'Learning and Adaptation'. In M. Augier & D. J. Teece (Eds.), The Palgrave Encyclopedia of Strategic Management. London: Palgrave Macmillan UK, pp. 1–5.
LEVITAN, B. & Kauffman, S. A. (1995). Adaptive walks with noisy fitness measurements. Molecular Diversity, 1(1), 53–68. [doi:10.1007/BF01715809 ]
LI, R., Emmerich, M. T. M., Eggermont, J., Bovenkamp, E. G. P., Bäck, T., Dijkstra, J. & Reiber, J. C. (2006). Mixed-Integer NK Landscapes, vol. 4193 of Lecture Notes in Computer Science, book section 5, (pp. 42–51). Springer Berlin Heidelberg.
LIU, P. & Li, Z. (2012). Task complexity: A review and conceptualization framework. International Journal of Industrial Ergonomics, 42(6), 553–568. [doi:10.1016/j.ergon.2012.09.001 ]
MALONE, T. W. & Crowston, K. (1994). The interdisciplinary study of coordination. ACM Comput. Surv., 26(1), 87– 119.
MARENGO, L., Dosi, G., Legrenzi, P. & Pasquali, C. (2000). The structure of problem-solving knowledge and the structure of organizations. Industrial and Corporate Change, 9(4), 757–788. [doi:10.1093/icc/9.4.757 ]
MARTIAL, F. v. (1992). Coordinating Plans of Autonomous Agents. Lecture Notes in Computer Science (LNCS). Berlin, Heidelberg: Springer.
POLHILL, J. G., Parker, D., Brown, D. & Grimm, V. (2008). Using the ODD protocol for describing three agent-based social simulation models of land-use change. Journal of Artificial Societies and Social Simulation, 11(2), 3: https://www.jasss.org/11/2/3.html.
REDMAN, T. C. (1998). The impact of poor data quality on the typical enterprise. Communications of the ACM, 41(2), 79–82.
RIVKIN, J. W. & Siggelkow, N. (2003). Balancing search and stability: Interdependencies among elements of organizational design. Management Science, 49(3), 290–311. [doi:10.1287/mnsc.49.3.290.12740 ]
RIVKIN, J. W. & Siggelkow, N. (2007). Patterned interactions in complex systems: Implications for exploration. Management Science, 53, 1068–1085.
SAH, R. K. & Stiglitz, J. E. (1986). The architecture of economic systems: Hierarchies and polyarchies. American Economic Review, 76(4), 716–727.
SIGGELKOW, N. & Levinthal, D. A. (2003). Temporarily divide to conquer: Centralized, decentralized, and reintegrated organizational approaches to exploration and adaptation. Organization Science, 14(6), 650–669.
SIGGELKOW, N. & Rivkin, J. W. (2005). Speed and search: Designing organizations for turbulence and complexity. Organization Science, 16(2), 101–122 [doi:10.1287/orsc.1050.0116 ]
SIMON, H. A. (1955). A behavioral model of rational choice. Quarterly Journal of Economics, 69, 99–118.
SIMON, H. A. (1962). The architecture of complexity. Proceedings of the American Philosophical Society, 106(6), 467–482.
SORENSON, O. (2002). Interorganizational complexity and computation., (pp. 664–685). Oxford, UK: Blackwell.
SUTTON, R. S. & Barto, A. G. (2012). Reinforcement Learning: An Introduction. Cambridge (Mass.): MIT Press, 2 edn.
TEE, S. W., Bowen, P. L., Doyle, P. & Rohde, F. H. (2007). Factors influencing organizations to improve data quality in their information systems. Accounting and Finance, 47(2), 335–355
THOMPSON, J. D. (1967). Organizations in Action. Social Science Bases of Administrative Theory. New York: McGraw-Hill.
VAN De Ven, A. H., Delbecq, A. L. & Koenig, R. (1976). Determinants of coordination modes within organizations. American Sociological Review, 41(2), 322–338
WALL, F. (2010). 'The (beneficial) role of informational imperfections in enhancing organisational performance.' In M. Li Calzi, L. Milone & P. Pellizzari (Eds.), Progress in Artificial Economics. , vol. 645 of Lecture Notes in Economics and Mathematical Systems, book section 10. Berlin Heidelberg: Springer, pp. 115-126. [doi:10.1007/978-3-642-13947-5_10 ]
WALL, F. (2016). Agent-based modeling in managerial science: an illustrative survey and study. Review of Managerial Science, 10(1), 135–193.
WALL, F. (2017). Learning to incentivize in different modes of coordination. Advances in Complex Systems, 20(0), 1–29. [doi:10.1142/S0219525917500035 ]
WELCH, B. L. (1938). The significance of the differences between two means when the population variances are unequal. Biometrika, 25, 350–362
WOOD, R. E. (1986). Task complexity: Definition of the construct. Organizational behavior and human decision processes, 37(1), 60–82 [doi:10.1016/0749-5978(86)90044-0 ]
YONGCAN, C., Wenwu, Y., Wei, R. & Guanrong, C. (2013). An overview of recent progress in the study of distributed multi-agent coordination. IEEE Transactions on Industrial Informatics, 9(1), 427–438.
ZSCHACHE, J. (2017). The explanation of social conventions by melioration learning. Journal of Artificial Societies and Social Simulation, 20(3), 1: https://www.jasss.org/20/3/1.html [doi:10.18564/jasss.3428 ]